AIによる無断コンテンツ学習問題:著作権法の境界線とクリエイター保護の未来

生成AIと著作権の衝突:なぜ今、問題なのか
2023年以降、生成AI(Generative AI)の急速な普及に伴い、AIによる無断コンテンツ学習問題が世界的な論争となっています。ChatGPT、Stable Diffusion、Midjourneyなどの生成AIは、インターネット上の膨大なテキスト、画像、動画を学習データとして利用していますが、その多くは著作権者の許諾を得ていません。
この問題は単なる法律論争ではなく、クリエイターの生存権、AI産業の発展、そして文化の未来に関わる根本的な対立です。本記事では、日本の著作権法、各国の法制度の違い、主要な訴訟事例、そして今後の展望について、10,000字を超える詳細な分析を提供します。
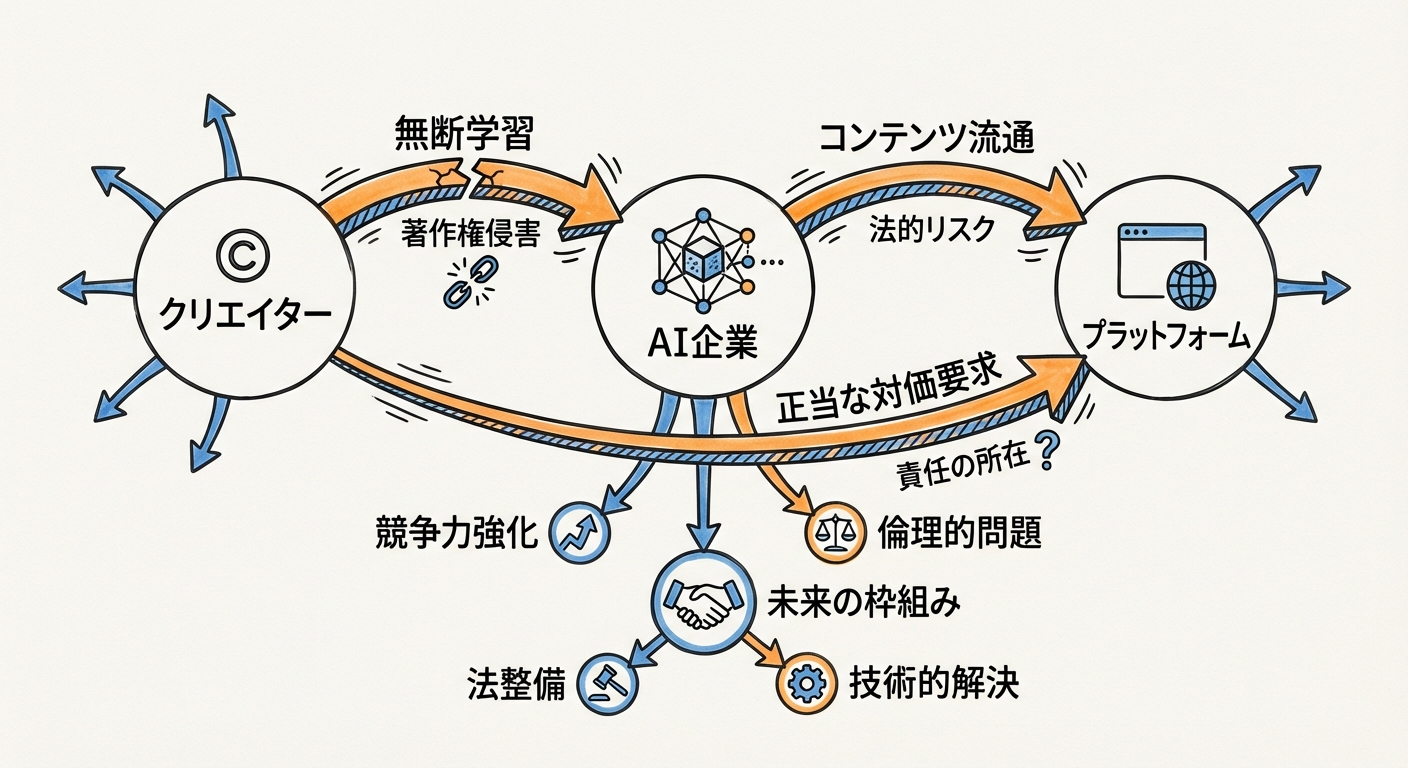
図1: AIによる無断学習をめぐる3者の対立構造(クリエイター、AI企業、プラットフォーム)
日本の著作権法第30条の4:「学習」と「利用」の境界
著作権法30条の4とは
日本では、2018年の著作権法改正により、第30条の4が新設されました。この条文は、「情報解析の用に供する場合」に著作物を利用できる例外規定を定めています。
条文の骨子:
著作権者の利益を不当に害しない限り、情報解析(データマイニング)を目的とする場合、著作物を利用できる
この条文により、日本ではAI学習のためのデータ収集・利用は原則として合法とされています。文化庁の解釈では、「非享楽的利用」(著作物を享楽的に鑑賞する目的でない利用)であれば、著作権侵害にあたらないとされています。
「学習」と「利用」の曖昧な境界線
しかし、問題は「学習」と「利用」の境界が極めて曖昧であることです。
学習段階(合法の可能性が高い):
- 大量のテキスト・画像をクロールしてデータセットを構築
- AIモデルの訓練に使用
- モデルのパラメータに情報が統計的に組み込まれる
利用段階(違法の可能性がある):
- 学習済みモデルが生成した作品が、元の著作物に酷似している
- 特定のクリエイターの作風を模倣した作品を商業利用
- 元の著作物を実質的に再現してしまう
文化庁の解釈では、生成AIの出力が既存の著作物と同一または類似する場合は、著作権侵害とみなされる可能性があります。しかし、「どの程度の類似性で侵害とするか」は個別のケースバイケースであり、明確な基準は存在しません。
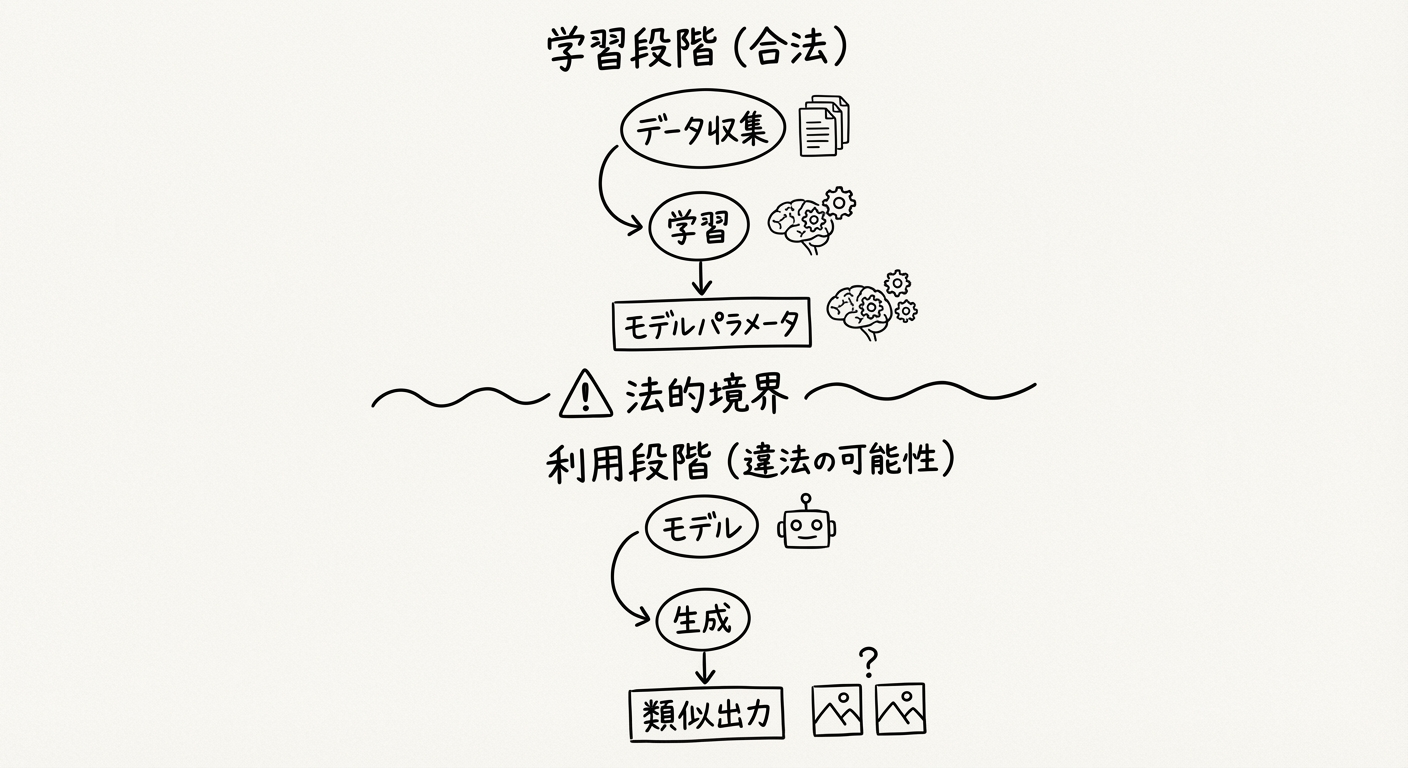
図2: AI学習段階(合法)と利用段階(違法の可能性)の境界。この境界の曖昧さが法的論争の核心
日本の法制度の特徴:「柔軟な権利制限規定」
日本の著作権法30条の4は、米国の「フェアユース」(後述)とは異なり、個別の行為類型ごとに例外を定める方式です。これは、予測可能性を高める一方で、技術革新に柔軟に対応しにくいという課題があります。
2024年の文化審議会著作権分科会では、「生成AIの学習と利用の区分をより明確化すべき」という意見が出されていますが、具体的な法改正には至っていません。
出典: 文化審議会著作権分科会「AIと著作権に関する考え方について」(2024年3月)
各国の法制度の違い:日本、EU、米国
米国:「フェアユース」による柔軟な判断
米国の著作権法は、第107条「フェアユース」(公正利用) を定めており、以下の4要素を総合的に判断して、著作権侵害か否かを決定します。
- 利用の目的・性格(商業的か、変容的か)
- 著作物の性質(創作的か、事実的か)
- 利用された部分の量・重要性
- 市場への影響(元の著作物の市場を害するか)
AI学習に関しては、「変容的利用」(Transformative Use)であるかが争点となります。つまり、元の著作物を単純にコピーするのではなく、新しい価値や意味を付与しているかが問われます。
主要な判例:
- Google Books事件(2015年): Googleの書籍検索サービスは、書籍全文をスキャンして検索可能にすることが「フェアユース」と認定されました。この判例は、AI学習のための大規模データ収集に有利な先例とされています。
EU:「著作権指令」とTDM例外
EUでは、2019年のデジタル単一市場著作権指令(DSM指令)により、テキスト・データマイニング(TDM: Text and Data Mining)のための例外規定が設けられました。
第3条(TDM例外:研究目的):
- 研究機関が科学研究目的でTDMを行う場合、著作権者の許諾なく利用可能
第4条(TDM例外:一般):
- 商業目的を含むTDMも、著作権者が明示的に利用を禁止していない限り許可される(オプトアウト方式)
ただし、EUの規定は著作権者が「利用禁止」を表明できる権利(オプトアウト権) を認めている点が特徴です。これは、日本や米国とは異なるアプローチです。
出典: EU Directive on Copyright in the Digital Single Market (2019/790)
各国比較表
| 国 | 法的根拠 | AI学習の扱い | 著作権者の権利 |
|---|---|---|---|
| 日本 | 著作権法30条の4 | 原則として合法(非享楽的利用) | オプトアウト権なし |
| 米国 | フェアユース(第107条) | ケースバイケースで判断(変容的利用が争点) | 裁判所が個別に判断 |
| EU | DSM指令第4条 | オプトアウト方式(著作権者が禁止を表明可能) | オプトアウト権あり |
表1: 各国のAI学習に関する著作権法の比較
主要訴訟事例:世界で起きている著作権紛争
1. New York Times vs OpenAI・Microsoft(2023年12月提訴)
2023年12月27日、New York Times(NYT)はOpenAIとMicrosoftを著作権侵害で提訴しました。これは、生成AI分野で最も注目される訴訟の一つです。
訴訟の概要:
- NYTは、ChatGPTがNYTの記事を無断で学習データとして使用し、記事内容をほぼそのまま出力することが可能であると主張
- 損害賠償額は数十億ドル規模に上ると見られる
- OpenAIは「フェアユース」を根拠に争う姿勢
争点:
- AI学習のためのデータ収集は「フェアユース」に該当するか
- ChatGPTの出力が元の記事と「実質的に類似」している場合、著作権侵害とみなされるか
- OpenAIが意図的に記事をそのまま出力させる機能を持たせていたか
現状(2026年1月時点):
- 裁判は継続中
- 2025年11月、裁判所はOpenAIに対し、学習データの詳細を開示するよう命令
- この判決は、今後のAI著作権訴訟の重要な先例となる可能性が高い
出典: The New York Times Company v. Microsoft Corporation and OpenAI, Inc., S.D.N.Y., Case No. 1:23-cv-11195
2. Getty Images vs Stability AI(2023年1月提訴)
画像ストックサービス大手のGetty ImagesはStability AI(Stable Diffusionの開発元)を提訴しました。
訴訟の概要:
- Stability AIが、Gettyの1,200万点以上の画像を無断で学習データに使用
- Stable Diffusionで生成された画像に、Gettyの透かし(ウォーターマーク)が残っている証拠を提示
- 英国と米国の両方で訴訟を提起
Stability AIの反論:
- AI学習は「変容的利用」であり、フェアユースに該当する
- 学習データとして使用しただけで、画像そのものを複製・配布していない
現状(2026年1月時点):
- 英国での訴訟は進行中
- 米国での訴訟は、2025年10月に一部の訴因が却下されたが、主要な争点は継続審理中
出典: Getty Images (US), Inc. v. Stability AI, Inc., D. Del., Case No. 1:23-cv-00135
3. 日本の新聞社 vs Perplexity AI(2024年11月提訴)
日本国内でも、2024年11月、読売新聞社、朝日新聞社、毎日新聞社などがPerplexity AIに対し、無断記事利用の停止を求める訴訟を提起しました。
訴訟の概要:
- Perplexity AI(AI検索エンジン)が、新聞記事を無断で学習し、検索結果として記事内容をほぼそのまま表示している
- 新聞社は、Perplexityに記事の削除とクロール停止を求めている
- robots.txtでクロールを禁止していたにもかかわらず、Perplexityは収集を継続していた疑い
争点:
- Perplexityの行為は著作権法30条の4の「情報解析」に該当するか
- 記事の要約・引用が「引用の範囲」を超えているか
現状(2026年1月時点):
- 裁判は継続中
- Perplexity AIは、2025年3月に日本の大手新聞社との間でライセンス契約交渉を開始したと発表
出典: 読売新聞「生成AI、記事無断利用で提訴」(2024年11月15日)
4. その他の主要訴訟
| 訴訟名 | 提訴時期 | 原告 | 被告 | 争点 |
|---|---|---|---|---|
| Authors Guild vs OpenAI | 2023年9月 | 作家団体 | OpenAI | 書籍の無断学習 |
| Sarah Silverman vs Meta | 2023年7月 | コメディアン | Meta | Llama2による書籍無断学習 |
| Andersen vs Stability AI | 2023年1月 | イラストレーター3名 | Stability AI, Midjourney | 画像生成AIによる作風模倣 |
| GitHub Copilot訴訟 | 2022年11月 | プログラマー複数 | GitHub, Microsoft, OpenAI | コード無断学習 |
表2: 主要なAI著作権訴訟一覧(2022-2026)
クリエイターの権利保護:オプトインとオプトアウトの議論
オプトアウト方式の問題点
現在、多くのAI企業はオプトアウト方式を採用しています。つまり、「デフォルトで全てのコンテンツを学習データとして利用可能」とし、著作権者が明示的に「利用禁止」を表明した場合のみ除外する、という仕組みです。
オプトアウト方式の例:
- robots.txt: ウェブサイトのクロールを禁止する標準的な方法
- Spawning AI の "Have I Been Trained?": クリエイターが自分の作品をAI学習から除外できるサービス
- Adobe の Content Credentials: 画像にメタデータを付与し、AI学習の可否を示す
問題点:
- 非対称な権利構造: 著作権者が能動的に「拒否」しなければ、自動的に利用される
- 実効性の欠如: robots.txtを無視するAI企業が存在する(Perplexity AIの事例)
- 負担の大きさ: 個々のクリエイターが全てのAI企業に対してオプトアウトを申請するのは現実的でない
オプトイン方式への転換要求
クリエイター団体や著作権団体は、オプトイン方式への転換を強く求めています。
オプトイン方式:
- デフォルトで全てのコンテンツは「利用禁止」
- AI企業は、著作権者から明示的な許諾を得た場合のみ学習データとして利用可能
メリット:
- 著作権者の権利が明確に保護される
- 許諾を得ることで、クリエイターへの対価還元の仕組みが構築しやすい
デメリット:
- AI開発のスピードが大幅に遅くなる可能性
- 中小クリエイターが個別に許諾を与えるのは現実的でなく、集中管理団体の役割が重要になる
robots.txtの限界と新しい技術的対策
robots.txtの問題:
- 法的拘束力がない(紳士協定に過ぎない)
- AI企業が無視しても罰則がない
新しい技術的対策:
-
C2PA(Coalition for Content Provenance and Authenticity)
- 画像や動画に「コンテンツ証明」メタデータを埋め込み、作者や編集履歴を追跡可能にする
- Adobe、Microsoft、Intel、BBCなどが参加する国際標準化団体
- AI学習の可否情報もメタデータに含めることが可能
-
Glaze・Nightshade
- イラストレーターが画像に「敵対的摂動」を加え、AI学習を妨害する技術
- University of Chicagoのチームが開発
- AIモデルが学習すると、出力結果が意図的に歪む
-
TDM Reservation Protocol
- 欧州で提案されている、AI学習の可否を機械可読形式で表明する標準規格
出典: C2PA公式サイト
出典: Glaze Project, University of Chicago
AI企業の対応:ライセンス契約と補償ポリシー
主要AI企業のライセンス契約
OpenAI:
- 2024年以降、Associated Press、Axel Springer、Le Mondeなど複数のメディア企業とライセンス契約を締結
- 契約内容は非公開だが、年間数百万ドル規模の支払いと見られる
Google:
- 2025年、日本の大手新聞社とライセンス契約を締結(報道)
- Geminiモデルの学習データとして正式に利用
Anthropic:
- 公式サイトで「著作権を尊重し、許諾を得たデータのみを使用」と表明
- ただし、具体的なライセンス契約の詳細は非公開
Meta:
- Llama 3モデルの学習に、公開データを広く使用していると発表
- ライセンス契約については明言せず
企業の補償ポリシー(Copyright Shield)
AI企業は、顧客が生成AIの利用により著作権侵害で訴えられた場合、法的費用を補償する「Copyright Shield」 を導入しています。
主要企業の補償ポリシー:
| 企業 | サービス名 | 補償内容 |
|---|---|---|
| Microsoft | Copilot Copyright Commitment | Azure OpenAI Serviceユーザーの法的費用を補償 |
| Indemnification | Google Cloudの生成AIサービスユーザーを保護 | |
| Adobe | Firefly Indemnity | Adobe Fireflyで生成したコンテンツの著作権侵害を補償 |
注意点:
- 補償は「企業顧客」に限定され、個人ユーザーは対象外のケースが多い
- ユーザーが「意図的に侵害」した場合は補償対象外
出典: Microsoft「Copilot Copyright Commitment」
クリエイターエコノミーへの影響
クリエイターの収益減少リスク
生成AIの普及により、特に以下の分野でクリエイターの収益減少が懸念されています。
影響を受けやすい分野:
- イラストレーション: Midjourney、Stable Diffusionによる画像生成で、イラストレーターの受注が減少
- ストックフォト: AI生成画像の台頭により、Shutterstockなどの売上が影響を受ける可能性
- 記事ライティング: ChatGPTによるコンテンツ生成で、ライターの需要が減少
具体的な事例:
- 2024年、米国のイラストレーター団体が行った調査では、回答者の58%が「AI生成画像により収入が減少した」 と回答
- ストックフォト大手Shutterstockは、2024年に自社のAI画像生成サービスを開始し、クリエイターへの報酬制度を導入
出典: Concept Art Association「AI Impact Survey」(2024)
新しいビジネスモデルの模索
一方で、AI時代に適応した新しいビジネスモデルも生まれています。
1. AI学習データのライセンス販売:
- ShutterstockやGetty Imagesは、AI企業に対して画像データをライセンス販売
- クリエイターには、自分の作品が学習データとして使用された場合、報酬が還元される
2. AIツールを活用したクリエイター:
- AIを補助ツールとして活用し、制作速度を向上させるクリエイターも増加
- 「AIでは作れない独自性」を強みにするクリエイターも登場
3. NFTとブロックチェーン:
- NFTによる作品の真正性証明
- ブロックチェーンで利用履歴を追跡し、二次利用にも報酬が発生する仕組み
今後の展望:法整備と技術的解決策
日本の法整備の動向
文化庁の検討事項(2025-2026年):
- 著作権法30条の4の解釈指針の明確化
- 生成AI出力物の著作権侵害判断基準の策定
- AI学習データの開示義務の導入
2026年1月現在、文化庁は「AIと著作権に関する考え方について」のパブリックコメントを実施しており、2026年内に新たなガイドライン策定を目指しています。
EU・米国の動向
EU:
- EU AI Act(2024年施行)により、高リスクAIシステムには透明性と説明責任が義務付けられる
- 著作権指令のTDM例外規定の運用状況を2026年にレビュー予定
米国:
- 米国著作権局が「AI and Copyright」に関する報告書を2026年夏に公表予定
- 連邦議会で「AI著作権法案」が複数提出されているが、成立は不透明
技術的解決策の進展
期待される技術:
- トレーサビリティ技術: AI学習データの出所を追跡可能にする仕組み
- 差分プライバシー: 個別のデータが特定されないようにしつつ、統計的有用性を保つ技術
- フェデレーテッドラーニング: データを中央に集めずに分散学習する手法
これらの技術により、「著作権者の権利を守りつつ、AI開発を促進する」ことが可能になると期待されています。
まとめ:企業とクリエイターが取るべき対策
AI企業が取るべき対策
- ライセンス契約の推進: 著作権者と正式な契約を結び、透明性を確保
- オプトアウトの実効性向上: robots.txt、C2PAなどの標準に確実に対応
- 補償ポリシーの拡充: 顧客だけでなく、クリエイターへの補償も検討
- 学習データの開示: どのようなデータを使用しているかを透明化
クリエイターが取るべき対策
- オプトアウトの積極的活用: Spawning AI、robots.txtなどでAI学習を拒否
- C2PA対応: 自分の作品にコンテンツ証明を付与
- 集団管理団体への加入: 個別対応は困難なため、業界団体を通じた権利行使
- AIツールの活用: 敵対するのではなく、補助ツールとして活用する道も模索
企業のAI利用者が取るべき対策
- 著作権侵害リスクの評価: 生成AIで作成したコンテンツを商業利用する前に、類似性チェックを実施
- 補償ポリシーの確認: 利用しているAIサービスが補償を提供しているか確認
- 社内ガイドラインの策定: 生成AIの利用ルールを明確化し、従業員に周知
おわりに:バランスの取れた未来を目指して
AIによる無断コンテンツ学習問題は、イノベーションとクリエイターの権利保護という、一見相反する2つの価値のバランスをいかに取るかという問題です。
日本の著作権法30条の4は「学習は自由、利用は制限」という原則を示していますが、その境界線は極めて曖昧です。米国では「フェアユース」の解釈が争われ、EUではオプトアウト権が認められています。
今後、主要な訴訟の判決が出ることで、法的な明確化が進むと期待されますが、最終的には技術的解決策(C2PA、差分プライバシーなど)と法的枠組みの両輪により、持続可能なエコシステムが構築されることが望まれます。
AI COMMONでは、生成AIの法的リスク評価から、社内ガイドラインの策定、AI活用戦略の立案まで、トータルでサポートしています。 AI利用における著作権リスクについてご検討の方は、ぜひお気軽にご相談ください。
参考文献
-
文化庁「AIと著作権」
https://www.bunka.go.jp/seisaku/chosakuken/hokaisei/h30_hokaisei/ -
文化審議会著作権分科会「AIと著作権に関する考え方について」(2024年3月)
https://www.bunka.go.jp/seisaku/bunkashingikai/chosakuken/ -
Authors Guild v. Google, Inc., 804 F.3d 202 (2d Cir. 2015) - U.S. Copyright Office Fair Use Index
https://www.copyright.gov/fair-use/summaries/authorsguild-google-2dcir2015.pdf -
EU Directive on Copyright in the Digital Single Market (2019/790)
https://eur-lex.europa.eu/eli/dir/2019/790/oj -
The New York Times Company v. Microsoft Corporation and OpenAI, Inc., S.D.N.Y., Case No. 1:23-cv-11195
-
Getty Images (US), Inc. v. Stability AI, Inc., D. Del., Case No. 1:23-cv-00135
-
C2PA (Coalition for Content Provenance and Authenticity)
https://c2pa.org/ -
Glaze Project, University of Chicago
https://glaze.cs.uchicago.edu/ -
Microsoft On the Issues「Copilot Copyright Commitment」
https://blogs.microsoft.com/on-the-issues/2023/09/07/copilot-copyright-commitment-ai-legal-concerns/ -
U.S. Copyright Office「Artificial Intelligence and Copyright」
https://www.copyright.gov/ai/ -
総務省「AI開発ガイドライン」
https://www.soumu.go.jp/main_content/000507517.pdf -
経済産業省(METI)「AI Guidelines for Business Ver1.0」(2024年4月19日)
https://www.meti.go.jp/english/press/2024/0419_002.html -
経済産業省・総務省「AI事業者ガイドライン(第1.0版)」
https://www.meti.go.jp/shingikai/mono_info_service/ai_shakai_jisso/20240419_report.html
📢この記事をシェアしませんか?
おすすめの投稿:
⚖️ 生成AIの無断コンテンツ学習問題が深刻化。日本の著作権法30条の4は「学習は自由、利用は制限」だが、その境界は?NYT vs OpenAI訴訟、Getty訴訟など主要事例とクリエイター保護策を解説
引用しやすいフレーズ:
“日本の著作権法30条の4は「学習は自由、利用は制限」という原則だが、その境界線は極めて曖昧”
“米国では2023年以降、著作権団体によるAI企業への訴訟が15件以上に急増”
“オプトアウト方式は「勝手に使って後で文句言われたら止める」という非対称な権利構造を生む”
“C2PA技術によるコンテンツ証明は、無断学習への技術的対抗手段として注目される”