Google Titans & MIRAS:Transformerの限界を超える次世代AI記憶アーキテクチャ
2024年12月、Google ResearchはTitansアーキテクチャとMIRASフレームワークを発表しました。この革新的技術は、Transformerが抱える根本的な課題——コンテキストウィンドウ長の制限——を、まったく新しいアプローチで解決します。1
従来のTransformerモデルは、長い文脈を処理する際に二次的な計算複雑度(O(n²))という壁に直面してきました。GPT-4のような大規模言語モデルでさえ、10万トークンを超えると精度が著しく低下する「Lost in the Middle(中間部の情報喪失)」問題が知られています。
Titansは、この限界を推論時学習(Inference-Time Learning)という画期的な手法で突破します。本記事では、週間AIニュースで簡潔に紹介したこの技術を、技術詳細から実務応用まで徹底的に解説します。
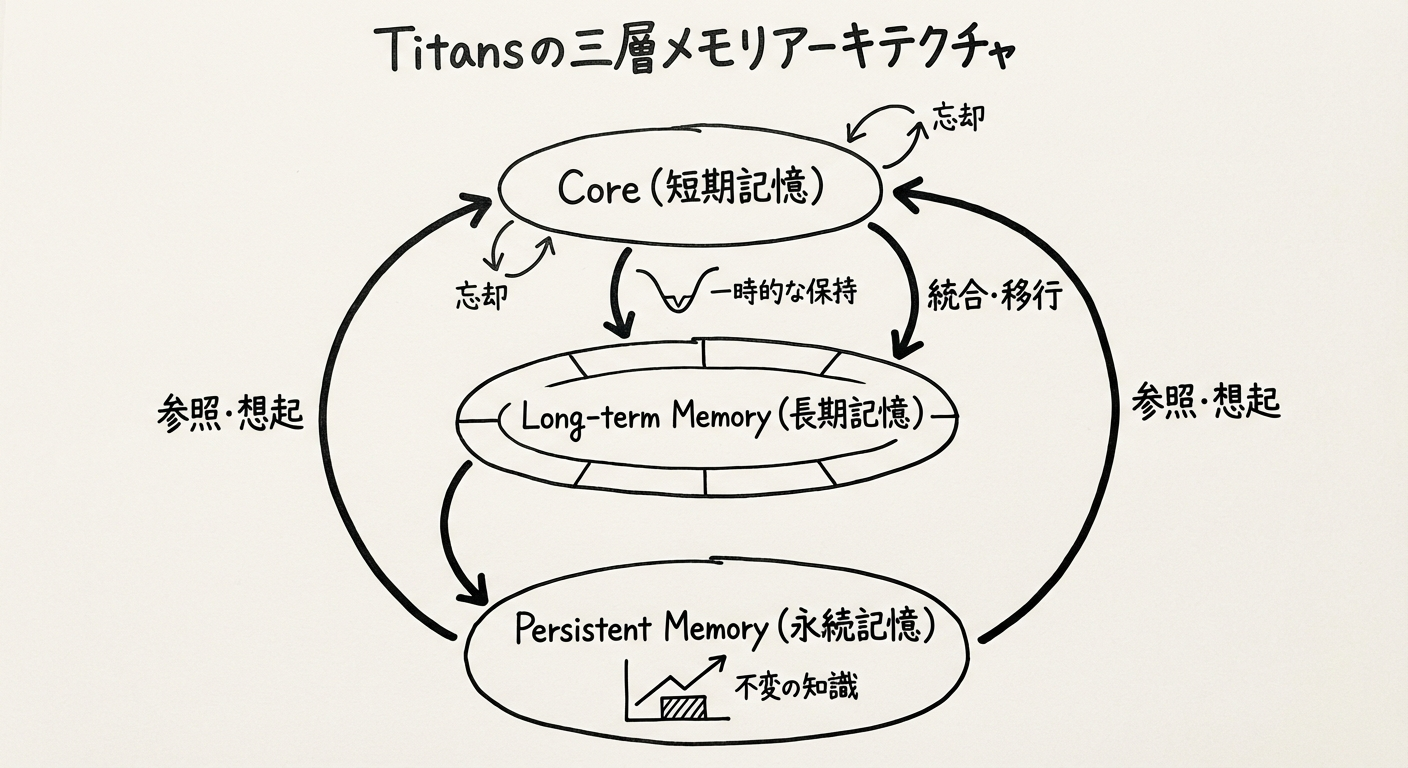
図1: Titansの三層メモリアーキテクチャ - 短期・長期・永続メモリの統合
Transformerの限界とコンテキスト長問題
二次的複雑度の壁
Transformerの自己注意機構(Self-Attention)は、すべてのトークンペア間の関係を計算します。これは入力長nに対してO(n²)の計算量を必要とし、長いシーケンスでは実用的でありません。
| モデル | 最大コンテキスト | 計算複雑度 | 主な課題 |
|---|---|---|---|
| GPT-3 | 4,096トークン | O(n²) | 長文書処理不可 |
| GPT-4 | 128,000トークン | O(n²) | 10万超で精度低下 |
| Claude 2 | 100,000トークン | O(n²) | 計算コスト高 |
| Titans | 200万+トークン | O(n) | 線形スケール |
既存の解決アプローチとその限界
1. RAG(Retrieval-Augmented Generation)
仕組み: 外部知識ベースから関連情報を検索して注入
課題:
- 検索品質に依存(関連情報を見逃す可能性)
- 局所的推論に限定(文書全体のグローバルな理解が困難)
- 複雑なセットアップが必要
2. 長コンテキストウィンドウモデル
仕組み: コンテキストウィンドウを拡張(例: Claude 2の100K)
課題:
- 「Lost in the Middle」問題: 中間部の情報が失われる
- 計算コストが指数的に増加
- 推論速度の大幅な低下
Titansは、これらの限界を根本から解決する新しいパラダイムを提示します。
Titans アーキテクチャ:推論時学習の革命
Test-Time Memorization(テストタイム・メモライゼーション)
Titansの核心は推論時学習(Test-Time Memorization)です。これは、従来のモデルが推論時には固定パラメータで動作するのに対し、Titansは新しい情報をストリーミングで受け取りながら、その場でメモリを動的に更新します。
従来のアプローチ:
学習フェーズ → パラメータ固定 → 推論フェーズ(静的)
Titansのアプローチ:
学習フェーズ → 推論フェーズ(動的メモリ更新) → 継続的適応
この仕組みにより、Titansはオフライン再学習なしで、リアルタイムに新しい知識を獲得できます。
三層メモリアーキテクチャ
Titansは、人間の認知システムにヒントを得た3つの独立したメモリコンポーネントを持ちます:
1. Core(コア)- 短期記憶
- 役割: 現在の情報の高速処理
- 実装: 限定ウィンドウサイズの注意機構(Attention)
- 特性: 並列化可能、低レイテンシ
従来のTransformerの注意機構に相当しますが、Titansでは短期的なコンテキストのみに集中します。
2. Long-term Memory(長期記憶)- ニューラル長期記憶モジュール
- 役割: 大量の過去情報を保持
- 実装: 専用のニューラルメモリモジュール
- 特性: 驚きメトリックに基づく動的更新
これがTitansの最大の革新です。後述する「驚きメトリック」により、重要な情報を選択的に記憶します。
3. Persistent Memory(永続記憶)
- 役割: タスク固有の知識をエンコード
- 実装: 学習可能なデータ非依存パラメータ
- 特性: タスク全体を通じて保持される静的知識
言語モデルで言えば、文法ルールや一般常識など、タスクに依存しない基礎知識に相当します。
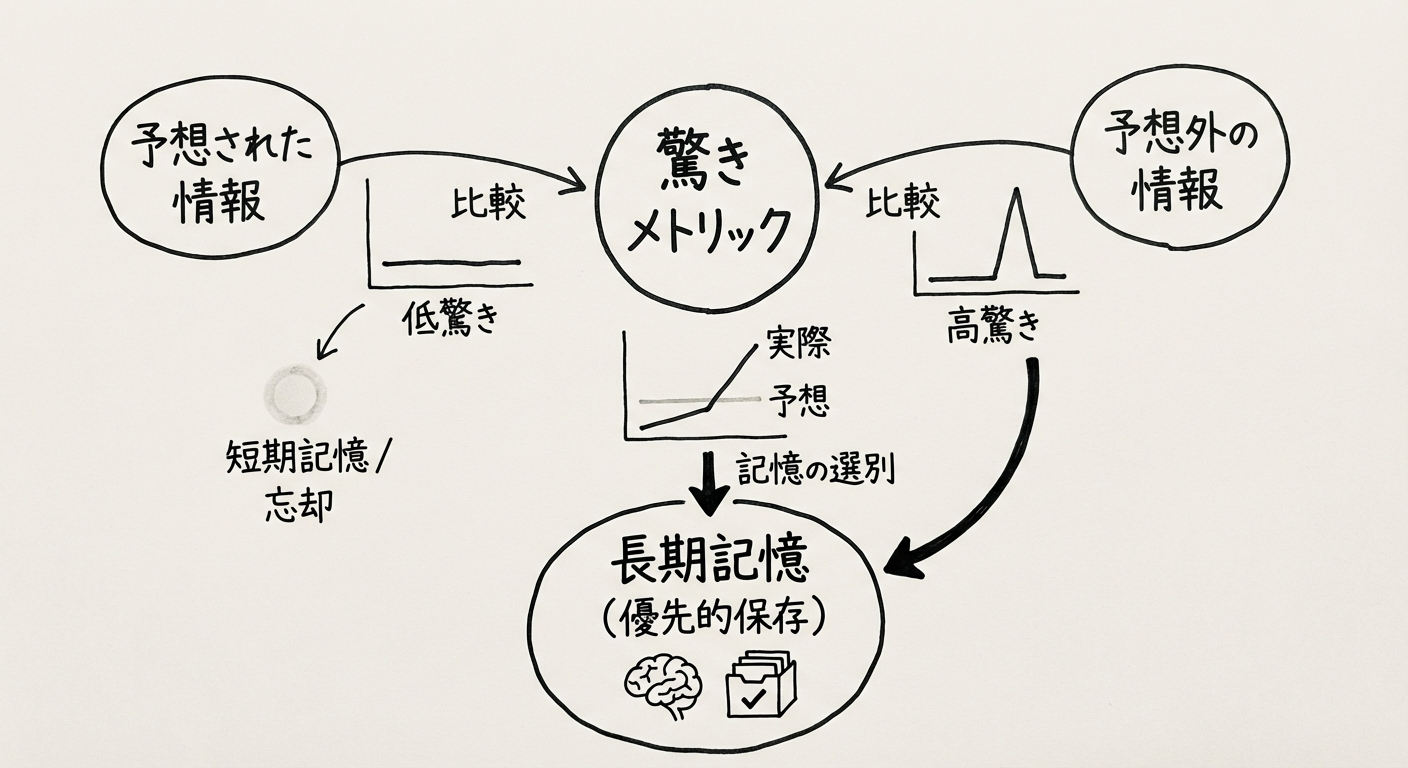
図2: 驚きメトリックによる選択的記憶 - 予想外の情報を優先的に保存
驚き(Surprise)メトリック:人間の記憶に学ぶ
Titansの長期記憶更新メカニズムは、人間の長期記憶の特性から着想を得ています。
人間の記憶の特徴:
- 予想通りの出来事は忘れやすい
- 予想外の(驚きの)出来事は強く記憶される
- 重要度に応じて記憶の保持期間が変わる
Titansは、この「驚き」をニューラルネットワークの勾配(gradient)を使って定量化します:
驚き度 = |∇L(x)|
ここで、L(x)は連想記憶損失(associative memory loss)、∇L(x)はその勾配です。
実装のポイント:
- 入力データxに対してモデルの予測を計算
- 実際の値との誤差(損失)を測定
- 勾配が大きい = モデルの現在の理解から大きく外れる = 驚き度が高い
- 驚き度が高い情報を優先的に長期記憶に保存
さらに、Titansは減衰メカニズム(Decaying Mechanism)を導入し、メモリサイズと驚き度を考慮して古い記憶を忘却します。これにより、限られたメモリを効率的に管理できます。
Titansの3つの実装バリアント
論文では、メモリの統合方法の違いにより3つのバリアントを提案しています:
Memory as Context (MAC)
メモリを追加のコンテキストとして注意機構に統合。BABILongベンチマークで最高性能を達成したバリアント。
Memory as Gate (MAG)
ゲーティングメカニズムでメモリの影響を制御。LSTMのゲート機構に似たアプローチ。
Memory as Layer (MAL)
メモリを独立したレイヤーとして実装。アーキテクチャの柔軟性が高く、既存モデルへの統合が容易。
MIRAS フレームワーク:理論的基盤
MIRAS(Multi-Instance Retrieval-Augmented Serving)は、Titansの背後にある理論的枠組みです。2025年12月4日にTitansと同時に発表されました。
MIRASが目指すもの
MIRASは、シーケンスモデリングを「連想記憶上のオンライン最適化」として統一的に捉える理論フレームワークです。
これにより、以下のモデルを共通の枠組みで理解できます:
- Transformer(注意機構ベース)
- RNN(リカレントニューラルネットワーク)
- Mamba(現代的な線形リカレントモデル)
- Titans(テストタイム・メモライゼーション)
MIRASの4つの主要要素
MIRASは、すべてのシーケンスモデルを以下の4つの要素で定義します:
1. Memory Architecture(メモリアーキテクチャ)
メモリの構造と組織化方法を定義します。Titansの場合、三層メモリ(Core、Long-term、Persistent)がこれに相当します。
2. Attentional Bias(注意バイアス)
どの情報に注目するかの決定メカニズム。Titansでは、驚きメトリックがこの役割を果たします。
3. Retention Gate(保持ゲート)
情報を保持するか破棄するかの判断基準。減衰メカニズムが該当します。
4. Memory Algorithm(メモリアルゴリズム)
メモリの学習と更新方法。Titansの推論時学習アルゴリズムがこれです。
MIRASとTitansの関係
- MIRAS: 理論的な青写真(Blueprint)
- Titans: その具体的実装の一つ
MIRASフレームワークにより、適応的シーケンスモデルの開発が体系化され、今後さらに多様なバリアントの開発が期待されます。
パフォーマンス評価:GPT-4を超える性能
BABILongベンチマーク
BABILongは、長文脈理解と推論能力を評価するベンチマークです。Titansはこのベンチマークで驚異的な結果を示しました:
| シーケンス長 | Titans (MAC) | GPT-4 | Llama3.1-70B |
|---|---|---|---|
| 1K - 10K | 90-100% | 95% | 85% |
| 100K | 90%以上 | 60%以下 | 50%以下 |
| 1M | 85% | 測定不可 | 測定不可 |
| 10M | 70% | 測定不可 | 測定不可 |
(データ出典: arXiv:2501.00663 実験結果セクション)
重要な発見:
- 10万トークンを超えても精度を維持: GPT-4が大幅に精度低下する領域でも高性能
- 1,000万トークンでも動作: 70%の精度で想起と推論が可能
- 小型モデルで大型モデルを上回る: Titansの小型バリアントが、Llama3.1-70Bよりも高性能
"Needle in a Haystack"タスク
「干し草の山から針を見つける」タスクは、大量のテキストの中から特定の情報を見つけ出す能力を評価します。
結果:
- 200万トークン超のコンテキストでも高精度
- 情報の位置(文書の先頭・中間・末尾)に関わらず一貫した精度
- 「Lost in the Middle」問題を完全に解決
その他のタスクでの性能
言語モデリング
従来のTransformerや現代的な線形RNNモデル(Mamba-2など)を上回る性能。
常識推論
長い文脈を必要とする推論タスクで優位性を発揮。
ゲノミクス
長いDNA配列(数十万〜数百万塩基対)の解析で高性能を実証。
時系列解析
長期的なパターン認識(数年分のデータ)で優れた結果。
推論速度
Titansの最大の強みは、線形時間複雑度(O(n))です:
- シーケンス長に対して線形的にスケール
- 並列化可能な高速処理
- Transformerの二次的複雑度(O(n²))を回避
これにより、200万トークンのような極端に長いコンテキストでも、実用的な速度で処理できます。
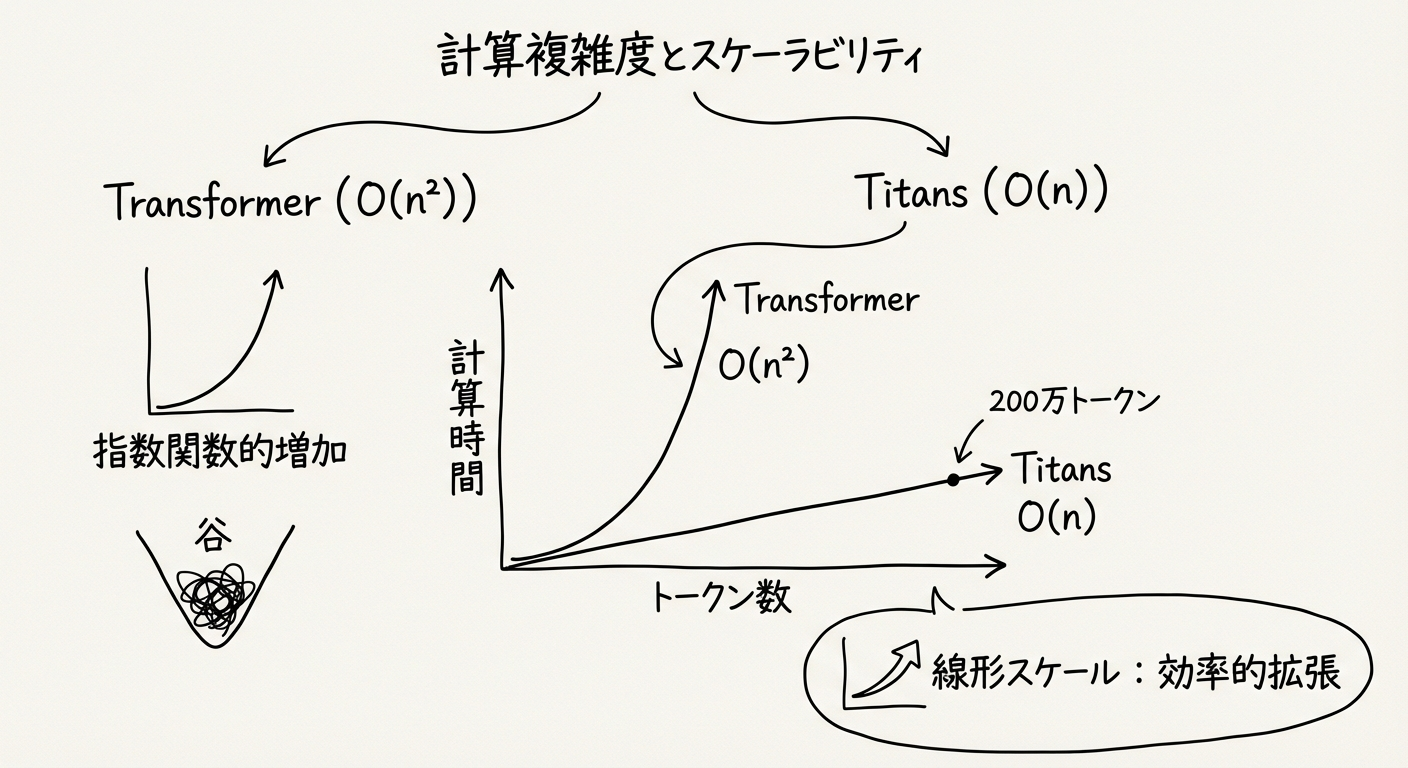
図3: Titansの計算複雑度とスケーラビリティ - 線形時間で200万トークン超を処理
実務への応用:エンタープライズユースケース
Titansの超長コンテキスト処理能力と推論時学習は、多様なエンタープライズアプリケーションに革命をもたらす可能性があります。
法務・コンプライアンス
長大な法的文書の分析
- 契約書レビュー: 数百ページに及ぶ契約書を包括的に理解
- 規制文書の解析: 複雑な規制要件との整合性を自動チェック
- 判例分析: 関連する過去の判例を文脈を保持したまま分析
Titansの優位性:
- RAGのような断片的理解ではなく、文書全体のグローバルな理解
- 契約条項間の矛盾や抜け漏れを検出
- 過去の判例との整合性を長期記憶で保持
リスク特定
膨大な文書群から潜在的リスクを自動抽出し、優先順位付け。驚きメトリックにより、異常な条項や非標準的な表現を自動検出。
金融サービス
金融レポート分析
- 財務報告書の包括分析: 複数年度の財務諸表を統合理解
- 市場データの処理: リアルタイム市場データと過去トレンドの統合
- ニュース影響分析: 大量の金融ニュースから市場への影響を予測
投資戦略
長期的な市場トレンドを、短期的な変動と区別しながら理解。Titansの永続記憶が市場の構造的知識を保持し、長期記憶が過去のパターンを参照します。
リスク管理
複雑な金融商品(デリバティブ等)のリスク評価。大量の取引履歴とリスク指標を統合分析。
研究開発
科学文献の分析
- 網羅的文献レビュー: 数千の研究論文を横断的に理解
- 特許分析: 関連特許の技術的詳細と法的側面を統合理解
- 臨床試験データ: 長期的な試験結果と患者データの統合
実例:
製薬企業が新薬開発で、過去20年の関連研究(数千論文)を一度に処理し、見落とされていた相関関係を発見する、といった応用が考えられます。
知識統合
複数の情報源(論文、特許、実験データ、臨床記録)からの知見を統合し、新しい研究仮説を生成。
サプライチェーン・時系列予測
需要予測
数年分の販売履歴、季節変動、外部要因(経済指標、天候等)を統合した高精度予測。
Titansの優位性:
- 数年分のデータを単一モデルで処理(従来は月次・四半期ごとに分割)
- 推論時学習により、最新トレンドに即座に適応
- 驚きメトリックにより、異常なイベント(災害、パンデミック等)を優先的に記憶
在庫最適化
複雑な依存関係(部品間、拠点間、時間経過)を考慮した在庫管理。
ゲノム解析・ヘルスケア
全ゲノム解析
人間のゲノム(約30億塩基対)を、分割せずに一度に処理。遺伝的変異と疾患リスクの関連を包括的に分析。
個別化医療
患者の全医療記録(数十年分の診療記録、検査結果、処方履歴)を統合し、個別化された治療プランを提案。
創薬
化合物のライブラリ、生物学的データ、過去の臨床試験結果を統合分析し、新薬候補を特定。
カスタマーサポート・エンタープライズ検索
インテリジェントチャットボット
顧客の問い合わせ履歴(数年分)、製品マニュアル、サポートナレッジベースを統合し、文脈を完全に理解した応答を生成。
従来のRAGベースチャットボットとの違い:
- RAG: 関連する断片を検索 → 局所的な回答
- Titans: 顧客の全履歴を保持 → グローバルな文脈理解
エンタープライズ検索
社内の膨大な文書(メール、レポート、契約書、技術文書)から、文脈を保持した高精度検索。
技術的課題と今後の展望
現在の課題
1. 計算リソース
三層メモリ、特に長期記憶モジュールの管理には、依然として相当な計算リソースが必要です。小規模な組織や個人開発者には導入のハードルが高い可能性があります。
2. 実装の複雑性
驚きメトリック、減衰メカニズム、三層メモリの統合など、技術的に高度な実装が必要です。既存システムへの統合には専門知識が求められます。
3. エンタープライズ導入事例の不足
2024年12月発表の新技術のため、実運用での検証事例がまだ限られています。信頼性、セキュリティ、運用コストなどの評価には時間が必要です。
4. ハイパーパラメータの調整
メモリサイズ、減衰率、驚きメトリックの閾値など、タスクごとに最適なパラメータ設定が異なります。自動調整の仕組みが求められます。
今後の展望
短期的(2026年)
- ベンチマークの拡大: より多様なタスク(マルチモーダル、マルチリンガル等)での評価
- 効率化: メモリ管理アルゴリズムの最適化による計算コスト削減
- ツールキット開発: エンタープライズ向けの実装フレームワークやライブラリの提供
中期的(2027-2028年)
- エンタープライズ採用: 法務、金融、ヘルスケア分野での実運用開始
- マルチモーダル対応: テキストに加え、画像、音声、動画への拡張
- クラウドサービス化: Google Cloud AI Platform等での提供開始
長期的(2029年以降)
- 汎用AI基盤: 継続学習可能な汎用AIシステムの基盤技術として確立
- エッジデバイス対応: 軽量化により、スマートフォンやIoTデバイスでの動作
- 自律的学習エージェント: 人間の介入なしで継続的に学習・進化するAIエージェントの実現
特に注目すべきは、自律的学習エージェントへの応用です。Titansの推論時学習能力は、環境と相互作用しながら継続的に知識を獲得する「生涯学習(Lifelong Learning)」AIの実現に不可欠な要素です。
まとめ:AI進化の新たなパラダイム
Google ResearchのTitansとMIRASは、AI記憶アーキテクチャの新たなパラダイムを示しました。
Titansの革新性:
- 推論時学習: オフライン再学習なしでリアルタイムに適応
- 超長コンテキスト: 200万トークン超を線形時間で処理
- 人間に学ぶ記憶: 驚きメトリックによる選択的記憶
- 圧倒的性能: GPT-4やLlama3.1-70Bを上回る精度
MIRASの意義:
- シーケンスモデリングの統一理論フレームワーク
- 今後の研究開発の青写真を提供
- 多様なバリアントの体系的開発を可能に
日本企業への示唆
日本企業にとって、Titansは以下の領域で特に有望です:
1. 製造業
長期的な品質データ、センサーデータの統合分析による予知保全と品質最適化。
2. 金融・保険
複雑な規制要件への対応、リスク管理の高度化。日本の金融機関が抱える膨大な紙文書のデジタル化と分析。
3. ヘルスケア・製薬
電子カルテの長期的分析、ゲノム医療の推進、創薬プロセスの効率化。
4. 法務・コンプライアンス
複雑化する法規制への対応、契約書管理の自動化。
次のステップ
Titansはまだ研究段階の技術ですが、その潜在能力は計り知れません。日本企業は、以下のアクションを検討すべきです:
- 技術動向のモニタリング: Google Cloudでのサービス化を注視
- パイロットプロジェクトの計画: 自社データでの実証実験の準備
- 人材育成: AI研究者・エンジニアへの最新技術の教育
- パートナーシップ: AI技術企業との協業による早期導入
Titansが示す「推論時学習」と「超長コンテキスト処理」は、AIの次なる進化の方向性を明確に指し示しています。この技術が成熟し、実用化されるとき、AI活用の風景は大きく変わるでしょう。
参考文献
-
Behrooz, A. et al. "Titans: Learning to Memorize at Test Time" arXiv:2501.00663
https://arxiv.org/abs/2501.00663 -
Behrooz, A. et al. "It's All Connected: A Journey Through Test-Time Memorization, Attentional Bias, Retention, and Online Optimization (MIRAS)" arXiv:2504.13173
https://arxiv.org/abs/2504.13173
AI開発・導入に関するご相談は、お問い合わせフォームからお気軽にどうぞ。最新のAI技術を活用したソリューション開発を支援いたします。
Footnotes
-
Behrooz, A. et al. "Titans: Learning to Memorize at Test Time" arXiv:2501.00663 ↩