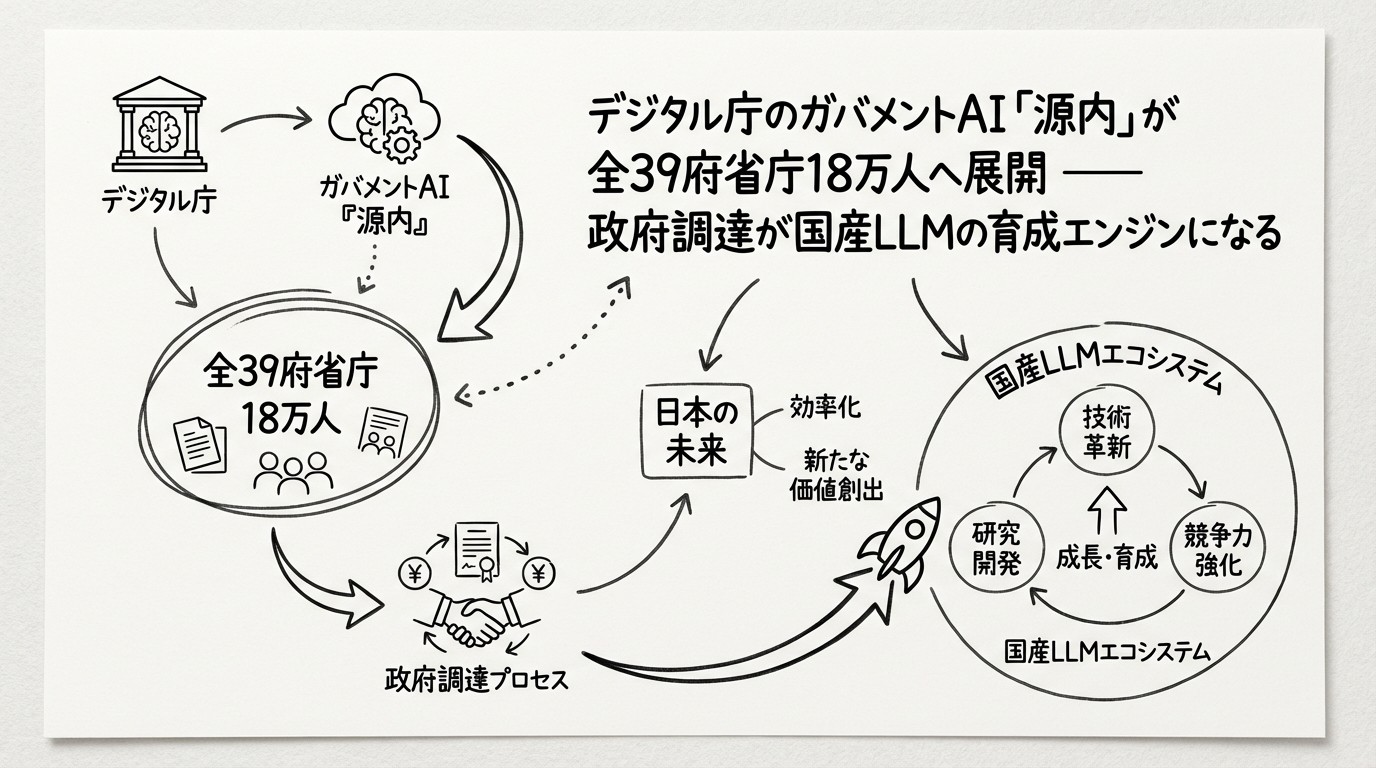
デジタル庁のガバメントAI「源内」が全39府省庁18万人へ展開 — 政府調達が国産LLMの育成エンジンになる
この記事は週間AIニュース(2026年4月13日週)の詳細版です。AnthropicのARR逆転、Claude Mythos発表など今週の主要AIニュースは元記事をご覧ください。
2026年度、日本のデジタル行政に歴史的な転換点が訪れています。デジタル庁が推進するガバメントAI「源内(げんない)」が、全39府省庁の約18万人の政府職員を対象に本格展開を開始しました。規模の大きさだけでなく、NTT・NEC・富士通・ソフトバンクなど日本を代表するIT企業が開発した国産LLM7モデルを行政の本番環境で評価するという前例のない試みが、日本のAI産業の構造を大きく変える可能性を秘めています。
本記事では「源内」の技術アーキテクチャと機能、評価対象の国産LLMの詳細、そして政府調達が日本のAI産業育成エンジンとして機能するメカニズムを徹底解説します。
背景と重要性:なぜ今「源内」なのか
行政DXの根本的な課題
日本の行政機関において、生成AIの業務活用は2023年以降急速に議論が進んできました。しかし、政府の業務は「機密性2」以上の情報を含む文書の取り扱いが日常的であり、情報漏洩リスクのある外部の商用AIサービスを安易に使用することは許されません。各府省庁が個別に安全なAI環境を構築するアプローチでは、整備コストの重複、セキュリティ水準の不均一、そして行政の縦割りによる連携の困難という三重苦が避けられませんでした。
「源内」はこれらの課題を一挙に解決する共通基盤として設計されています。単一の高セキュリティ環境を全府省庁で共有することで、コストの分散と標準化された安全基準の確保を両立します。
「源内」という名前の意味
「源内」は江戸時代の発明家・平賀源内にちなんで命名されています。エレキテル(摩擦起電機)や土用の丑の日のウナギ普及など、実用的なイノベーションで知られる源内の精神は、「技術を行政の実務に役立てる」というガバメントAIのコンセプトと合致しています。
「源内」の技術アーキテクチャと機能
セキュリティアーキテクチャ
「源内」の設計で最も重視されているのがセキュリティです。政府情報システムのセキュリティ基準である「機密性2」に完全対応した閉域ネットワーク環境上に構築されており、ユーザーが入力したプロンプトやその応答が外部のモデルプロバイダーのサーバーに送信されることはありません。
具体的なセキュリティ要件は以下の通りです。
- 閉域ネットワーク環境: 政府イントラネット内での完結処理
- データの内部保持: プロンプト・応答データの外部送信禁止
- アクセス制御: 府省庁・役職に応じた段階的なアクセス権限管理
- 監査ログ: 全操作の完全記録と定期的な監査
- 暗号化: 通信・保存データの強制暗号化
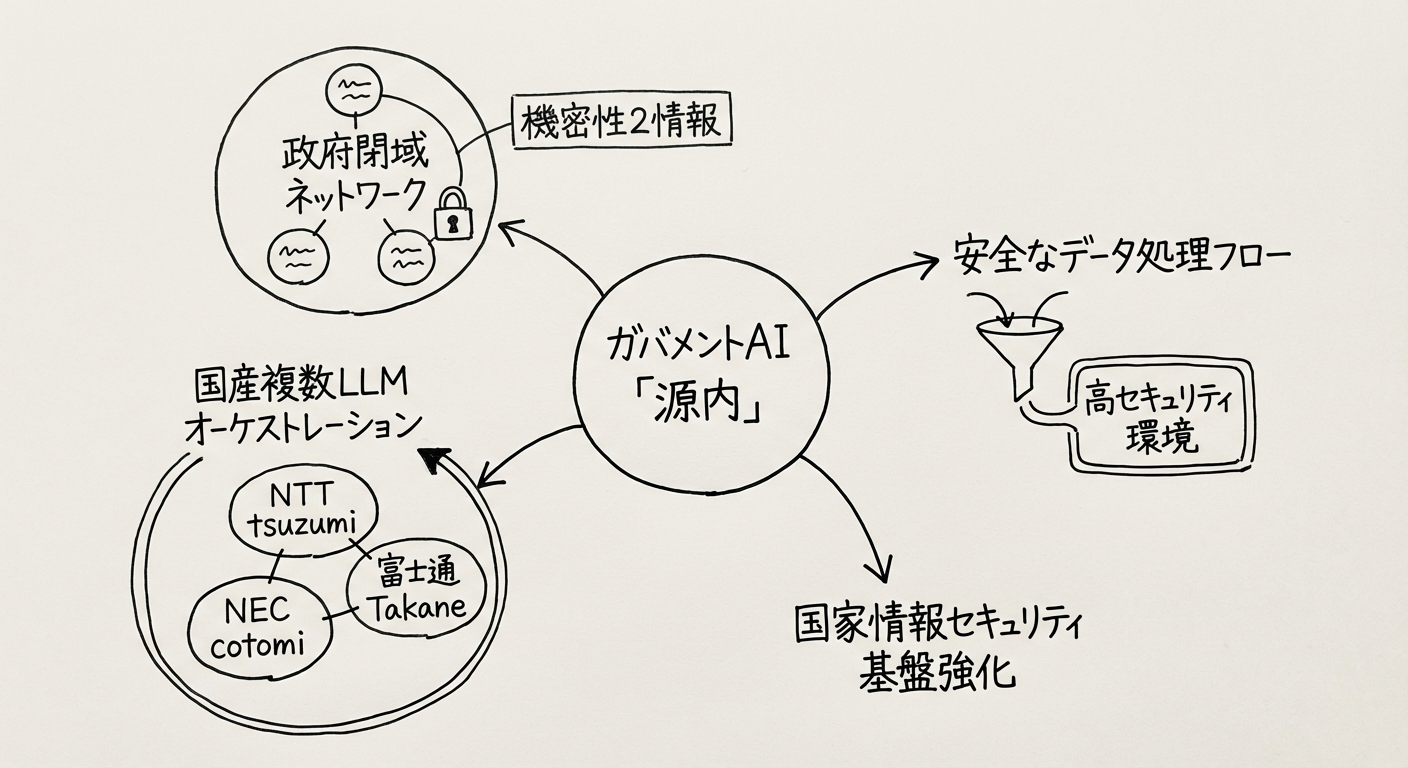
図1: 「源内」のセキュリティ設計概念図。政府イントラネット内の閉域環境で複数の国産LLMをオーケストレーションし、機密性2情報の安全な処理を実現する
20種類以上の行政特化アプリケーション
「源内」が単なるチャットUIと異なる最大の特徴は、行政実務に特化した20種類以上のアプリケーションが実装されている点です。主要なアプリケーションを以下に整理します。
立法支援系
- 国会答弁検索AI: 過去の国会答弁データベースを基に類似質問への答弁案を自動生成。議員から寄せられた質問に対して、省庁担当者が答弁書を作成する工数を大幅に削減
- 法制度調査AI: 法令・判例・行政解釈をナレッジベース化し、法改正や新規立法時の調査を支援
行政管理系
- マニュアルベースのヘルプデスクAI: 各府省庁の業務マニュアルを学習させ、職員からの業務手続きに関する問い合わせに自動回答
- 文書要約・翻訳AI: 膨大な行政文書の要約生成と、英語・中国語・韓国語への翻訳支援
政策分析系
- 統計・データ分析AI: 政府統計データを基にした可視化・分析レポートの自動生成
- パブリックコメント分析AI: 政策パブリックコメントの傾向分析と代表的意見の抽出
マルチモデルオーケストレーション
「源内」の技術的な革新性のひとつが、複数の国産LLMを目的に応じて使い分けるマルチモデルオーケストレーション機能です。タスクの種類・機密レベル・言語要件に応じて最適なモデルを動的に選択し、必要に応じて複数モデルの出力を統合する仕組みが実装されています。
評価対象の国産LLM 7モデル詳細
「源内」のアーキテクチャの中核をなす国産LLM7モデルの評価プログラムは、単なる性能テストではありません。18万人の政府職員が日々の業務でこれらのモデルを使用し、実際の業務文書・法令・公用文の処理品質についてフィードバックを開発ベンダーに還元することで、行政実務に特化した日本語LLMの性能向上を図る官民共同開発の仕組みです。
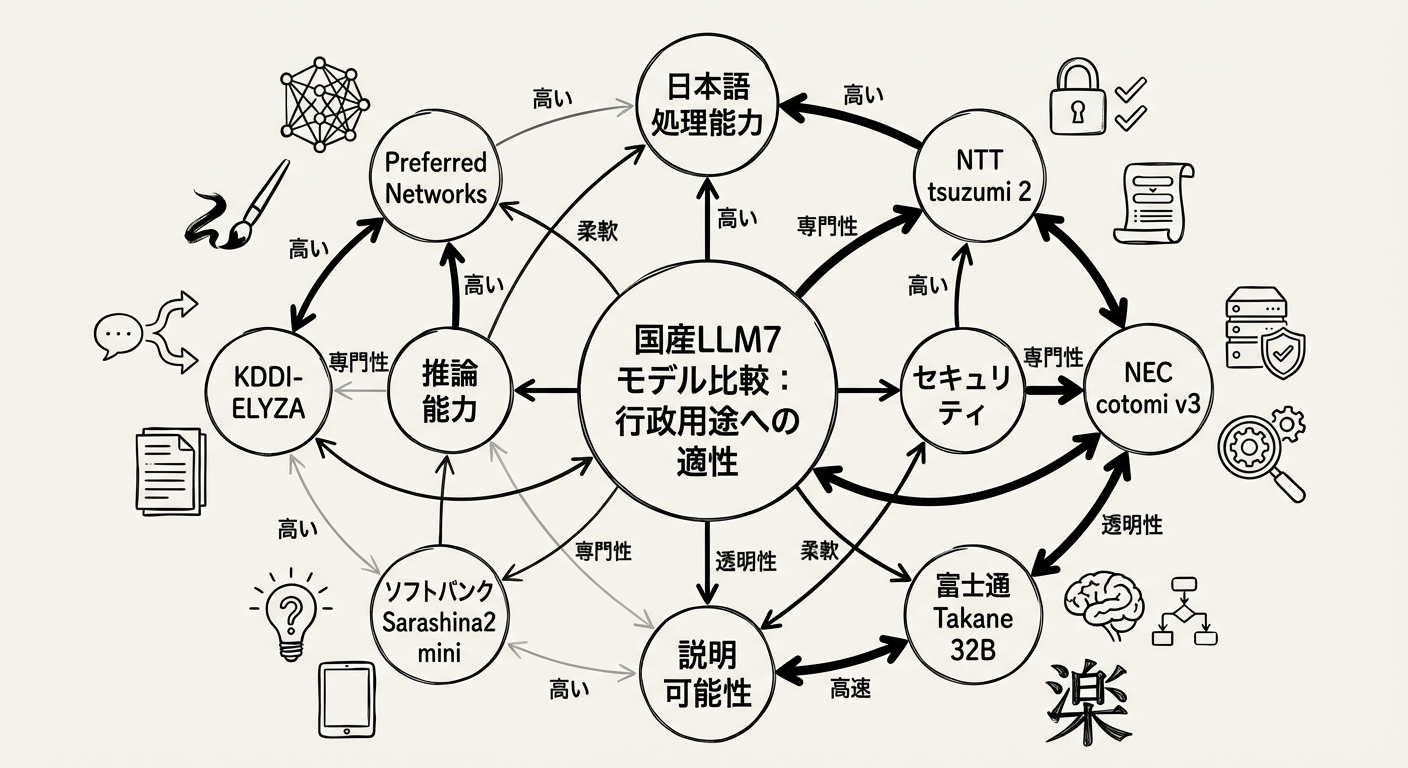
図2: 「源内」で評価される国産LLM7モデルの特徴と行政用途適性の概念図。各モデルの強みに応じた用途割り当てが行われる
1. NTT「tsuzumi 2」
NTT(日本電信電話)が開発した「tsuzumi(鼓)」シリーズの第2世代モデルです。tsuzumiシリーズは、軽量・高効率なアーキテクチャを特徴とし、特定業務ドメインへのファインチューニングが容易な設計で知られています。
初代tsuzumiは2024年に公開され、法律・医療・金融などの特定ドメインでの高精度な日本語処理能力で注目を集めました。tsuzumi 2では、基盤モデルの規模拡大とともに、推論能力と長文理解能力の大幅な向上が図られています。NTTグループが保有する膨大な通信・サービスデータを活用した継続事前学習も特徴のひとつです。
行政用途における期待値は高く、NTTの法人向けビジネスで培った業務文書処理の実績が「源内」への適用に強みを発揮すると見られています。
2. NEC「cotomi v3」
NECが開発する「cotomi(ことみ)」シリーズの第3世代モデルです。cotomiはNECが独自に収集・整備した日本語コーパスで事前学習されており、日本語の微妙なニュアンス表現や公用文特有の文体への対応に強みを持ちます。
v3では特に、長文の政策文書・法令・議事録といった行政特有の文書形式への対応が強化されたとされています。NECはgotomi(v1)の段階から政府機関との実証実験を重ねており、行政文書の要約・翻訳・Q&A生成における実績データを蓄積しています。セキュリティ面でも、NECの防衛・公共向けシステム構築の長年の経験が「源内」の閉域環境構築に活かされています。
3. 富士通「Takane 32B」
富士通が開発した「Takane(高嶺)」は、その名が示す通り高い性能水準を目指したフラッグシップモデルです。32Bというパラメータ規模は、国産LLMの中でも大規模なモデルに分類されます。
Takane 32Bの特徴は、富士通が長年にわたって積み上げてきたスーパーコンピュータ「富岳」を用いた大規模計算技術の知見を活用した効率的な学習アーキテクチャにあります。高い推論能力と、技術的・専門的な内容を含む複雑な文書処理における精度が評価されており、法制度調査や統計分析支援のような高度な認知タスクへの適用が期待されています。
富士通は政府・自治体向けシステムインテグレーションで国内最大規模の実績を持つことから、行政システムとのシームレスな連携においても優位性があります。
4. ソフトバンク「Sarashina2 mini」
ソフトバンクが開発する「Sarashina(更科)」シリーズの軽量版モデル「Sarashina2 mini」です。「mini」の名称が示す通り、大規模モデルの性能を維持しながら推論速度と計算効率を最適化した設計です。
Sarashinaシリーズは、ソフトバンクの通信・インターネットサービスで生成される大量の日本語テキストデータを活用した事前学習が特徴です。多くのユーザーとの対話履歴から学習された自然な日本語生成能力と、業務システムへの組み込みを想定した軽量・高速な推論性能が「源内」のヘルプデスクAIや問い合わせ対応用途での採用を後押ししています。
5. KDDI-ELYZA共同モデル
KDDIと東京大学松尾研究室発のAIスタートアップELYZAが共同開発したモデルです。ELYZAは国内LLM開発の先駆者として、Llama系オープンソースモデルの日本語対応(ELYZA-japanese-Llama)で広く知られてきましたが、KDDIとの連携により法人向けの大規模モデル開発に踏み込んでいます。
KDDIの法人事業で培った業務特化の知見とELYZAの日本語LLM技術の融合は、特に中小規模自治体での行政業務DXでの実績が期待される組み合わせです。オープンソースモデルをベースにしたアーキテクチャは、行政機関によるモデルの監査・検証が比較的容易であるという透明性の面でも利点があります。
6. Preferred Networks(PFN)モデル
ディープラーニング分野の国内トップ研究機関として知られるPreferred Networks(PFN)が開発したモデルです。PFNはトヨタ・ファナック・NTTなどと協力した産業用AIロボティクスの実績で世界的に評価されており、今回初めて大規模言語モデル分野への本格参入となります。
PFNのモデルは、純粋な研究機関としての技術的厳密性と、産業用途への展開経験が特徴です。「源内」の評価対象として含まれることで、PFNの言語モデル研究が産業実用化へのフィードバックループを獲得することになります。
7. 追加評価モデル
上記6モデルに加え、デジタル庁は非公開の追加モデルも含めた計7モデル体制での評価を実施しています。国内AI産業の多様性を担保するため、大手のみならず新興スタートアップや大学発ベンチャーのモデルも評価対象に含まれる可能性が示唆されています。
政府調達が国産AI産業に与える影響
官製需要の育成効果メカニズム
政府調達が産業育成エンジンとして機能するメカニズムは、いくつかの経路で作用します。
第一の経路:規模の学習効果
18万人の政府職員が日常業務でAIを使用することで、モデルに対する膨大なフィードバックが蓄積されます。商用サービスでは通常クローズドになる「実際の業務文書でのAI性能データ」が、開発ベンダーに還元されることで、国産LLMの業務適用精度が急速に向上します。
第二の経路:信頼の証明
政府機関が国産LLMを採用するという事実そのものが、民間企業に対する強力な「信頼の証明(Proof of Trust)」として機能します。特に金融・医療・法務など高いセキュリティと信頼性が求められる分野での民間採用を後押しします。
第三の経路:標準化の牽引
デジタル庁が策定する行政AI利活用ガイドラインは、事実上の業界標準として民間にも影響します。行政向けに設計されたセキュリティ・説明責任・ガバナンスの基準が、民間エンタープライズ向けAI調達の参照基準になっていく構造です。
歴史的な類似事例との比較
政府調達が特定技術の産業育成エンジンとして機能した歴史的な事例として、インターネット(ARPANETからの展開)、GPS技術(米国防総省の民間開放)、そして半導体産業(米国防省調達による量産効果)が挙げられます。
日本でも、1970〜80年代の通産省によるスーパーコンピュータ開発プロジェクトが、現在の富士通・NEC・日立の計算機産業の礎を築いた事例があります。「源内」プロジェクトは、この系譜に連なる「官製育成」の現代版として位置付けられています。
行政DXの要件と民間への波及効果
CAIO(Chief AI Officer)制度の義務付け
デジタル庁が改定中の生成AI調達・利活用ガイドラインで最も注目すべき変更点のひとつが、各府省庁へのCAIO(Chief AI Officer)配置の義務付けです。CAIOはAIシステムの導入判断、リスク評価、ガバナンス体制の構築に責任を持つ役職です。
この動きは民間企業にも大きな示唆を持ちます。政府機関がCAIOを設置することで、民間との取引においてAIガバナンスの成熟度が評価基準として浮上します。政府調達に参入を目指すITベンダー・SIerは、自社のAIガバナンス体制の整備が急務となります。
高リスクAI利用の判断基準の設定
改定ガイドラインは「高リスクなAI利用」の判断基準を明文化することも予定しています。EU AI Actが導入したリスクベースアプローチと整合した基準が、日本の行政AIにも適用されることになります。
具体的には以下の利用ケースが高リスクに分類される見通しです。
- 個人の権利・給付に影響する行政処分へのAI活用
- 捜査・司法関連の判断支援
- 国家安全保障に関わる情報処理
- 医療診断・治療推奨への直接適用
説明可能AI(XAI)要件の強化
行政におけるAI活用では、市民に対する決定の説明責任が求められます。この要件は「ブラックボックスAI」の導入を制限し、モデルの判断根拠を説明可能な仕組み(Explainable AI)の整備を義務付けます。
国産LLMが評価対象として選定される背景には、この「説明可能性」の要件も関係しています。国内ベンダーであれば、モデルアーキテクチャ・学習データ・評価プロセスについて政府機関による監査・検証が海外モデルに比べて容易であるという利点があります。
日本企業への示唆
SIer・ITベンダー:政府向け要件を民間の差別化軸に
行政DXの要件(高セキュリティ・高い説明責任・日本語処理の精度・ガバナンス体制の成熟度)は、民間エンタープライズ市場でも共通のニーズです。政府向けの要件を満たすソリューションの構築が、最も厳しい民間顧客向けの「信頼の証明」となります。
具体的には、以下のような戦略が有効です。
1. 閉域環境AIの専門性確立
「源内」が採用した閉域ネットワーク型AIアーキテクチャは、医療・金融・製造業など機密情報を扱う民間エンタープライズでも需要が高まります。政府向け実績を持つベンダーが、民間向け「オンプレミス型プライベートAI」の構築専門家として差別化できるポジションが生まれます。
2. AIガバナンス体制の構築支援
CAIO設置の義務付けやリスク分類基準の明文化に伴い、企業のAIガバナンス体制構築を支援するコンサルティングサービスの需要が急増します。政府のガイドライン解釈と企業ポリシーへの落とし込みを支援する専門サービスは、AI導入が本格化する大企業・中堅企業の共通ニーズです。
3. 行政実務特化AIの民間転用
国会答弁支援AIや法制度調査AIで培われた技術は、民間の法務・コンプライアンス・規制対応業務にも直接転用できます。行政の用途で磨かれた日本語法令処理能力を持つAIは、日本の法規制の複雑さから生じる民間ニーズにも応えられます。
国産LLM開発企業:政府需要を梃子にした国際展開
「源内」の評価プログラムに参加する国産LLM開発企業にとって、18万人の政府職員との日常的なインタラクションから得られるデータは、海外モデルとの技術格差を縮める貴重な資産です。
行政実務での高い品質基準をクリアした国産LLMは、日本と同様に行政DXを推進する東南アジア・中東・アフリカ諸国への輸出可能な「実績付きプロダクト」としての価値を持ちます。日本語特有の形態素解析・敬語処理・公用文体への対応能力は、日本語を公用語とする市場での参入障壁にもなります。
一般企業:調達基準の先読みで先行優位を確保
政府のAI調達ガイドラインは、民間企業の取引先選定基準や社内コンプライアンスポリシーにも影響します。ガイドライン改定の方向性を先読みして、早期にAIガバナンス体制を整備した企業は、政府調達への参入資格を得るとともに、民間取引においても「AI利活用の先進企業」としての評価を獲得できます。
今後の展望
2026〜2027年:評価フェーズから本番導入へ
2026年度の展開は大規模な実証実験の性格を持っています。18万人の政府職員の日常利用を通じて蓄積されたデータと知見を基に、2027年度以降は本格的な全面導入フェーズへの移行が想定されています。
評価の重点指標として以下が設定されていると見られます。
- 業務効率化効果(文書作成時間の短縮率)
- 回答精度(法令・政策情報の正確性)
- ユーザー満足度(職員の利用継続意向)
- セキュリティインシデント発生率
- コスト対効果(導入コストと効率化効果の比率)
地方自治体への展開
全国の都道府県・市区町村(約1,800団体)への「源内」展開も視野に入っています。地方自治体では特に、人口減少・職員の高齢化・業務の複雑化という三重苦の解決手段としてAIへの期待が高まっており、政府実績のある共通基盤の横展開は合理的な選択肢です。
地方展開では、地方議会の議事録解析・地域住民の問い合わせ対応・農業・観光など地域産業特有の業務支援といった、中央官庁とは異なる用途への対応が新たな課題となります。
アジア圏への横展開
「源内」のアーキテクチャと評価プログラムから生まれた知見は、デジタル行政のインフラとして東南アジア諸国(特にODA供与先)への展開も想定されています。デジタル庁・外務省・経産省が連携した「ガバメントAIの輸出モデル」として、日本のDX支援と国産LLMの海外展開を組み合わせた政策パッケージの構想が進んでいます。
国産AI産業の自立に向けた課題
政府調達による育成効果は大きいものの、日本の国産LLM産業が中長期的に自立するためには解決すべき課題も残っています。
計算資源の確保: 大規模LLMの学習・推論に必要なGPUクラスターは現在も不足しており、NVIDIAのBlackwellが2026年半ばまで完売という状況下で、国内データセンターへのGPU調達は困難を伴います。
データの品質と量: 日本語の高品質なトレーニングデータは英語に比べて絶対量が少なく、行政・法務・医療など専門分野の学習データの整備が国産LLMの性能向上の鍵を握ります。
人材の確保: AI研究者・エンジニアの国内育成と、海外からの優秀な人材誘致が中長期的な競争力の源泉です。「源内」プロジェクトが産学官連携のハブとなり、AI人材のキャリアパスを提供する機能も期待されています。
まとめ:政府調達が描く日本AI産業の未来
デジタル庁のガバメントAI「源内」は、単なる政府内AI導入プロジェクトの枠を超えた、日本のAI産業政策の大きな実験場です。18万人の公務員が日々の業務で国産LLMを「普段使い」し、そのフィードバックが開発ベンダーに還元される官民共同開発の仕組みは、市場競争だけでは生まれにくい「行政特化の日本語AI」を育てる唯一の経路かもしれません。
NTT・NEC・富士通・ソフトバンク・KDDI-ELYZAという日本のIT産業の主力企業が揃ってこのプロジェクトに参画し、政府の評価を受けるという構図は、国産AI産業の産業標準形成においても重要な意味を持ちます。
行政DXの要件(高セキュリティ・説明可能性・日本語精度・ガバナンスの成熟度)は、民間エンタープライズ市場での要求とも重なります。政府向け要件を満たすことで得られる「信頼の証明」を足がかりに、国産AI産業が官製需要から自立し、グローバル市場でも競争力を持つモデルを育てていく——「源内」はその壮大な実験の第一歩です。
関連記事
- 日本政府のAI主権戦略と国産AI開発の展望 — 1兆円投資の全体像
- ガバメントAI防衛利用の動向 — 防衛省でのAI活用
- 日本のPhysical AI政策 — 物理AIへの政策展開
- 週間AIニュース(2026年4月13日週) — 今週の全AI動向
AI COMMON へのお問い合わせ
ガバメントAI対応や、行政・公共向けAI導入のご支援、国産LLMを活用したセキュアなAI基盤の構築についてご相談ください。AI COMMONでは、政府・自治体・民間企業を問わず、AI導入の戦略立案から実装・運用まで一気通貫でサポートしています。
お問い合わせはこちら から、ぜひお気軽にご相談ください。
📢この記事をシェアしませんか?
おすすめの投稿:
デジタル庁のガバメントAI「源内」が全39府省庁18万人へ展開。国産LLM7モデルを政府が本番評価する前例のない試みが、日本のAI産業を育成するエンジンになる理由を解説。
引用しやすいフレーズ:
“18万人の公務員が日々の業務で国産LLMを『普段使い』することで、行政実務に耐えうる日本語AIの性能向上が実現する”
“政府向けのセキュリティ・説明責任要件を満たすことが、最も厳しい民間顧客への『信頼の証明』になる”
“ガバメントAI「源内」は単なるチャットUIではなく、行政DXの共通基盤インフラだ”
“国産LLM7モデルの本番評価は、日本のAI産業が官製需要から自立するための最初のステップ”