LLM継続学習完全ガイド:破壊的忘却を克服する最新技術と実装手法
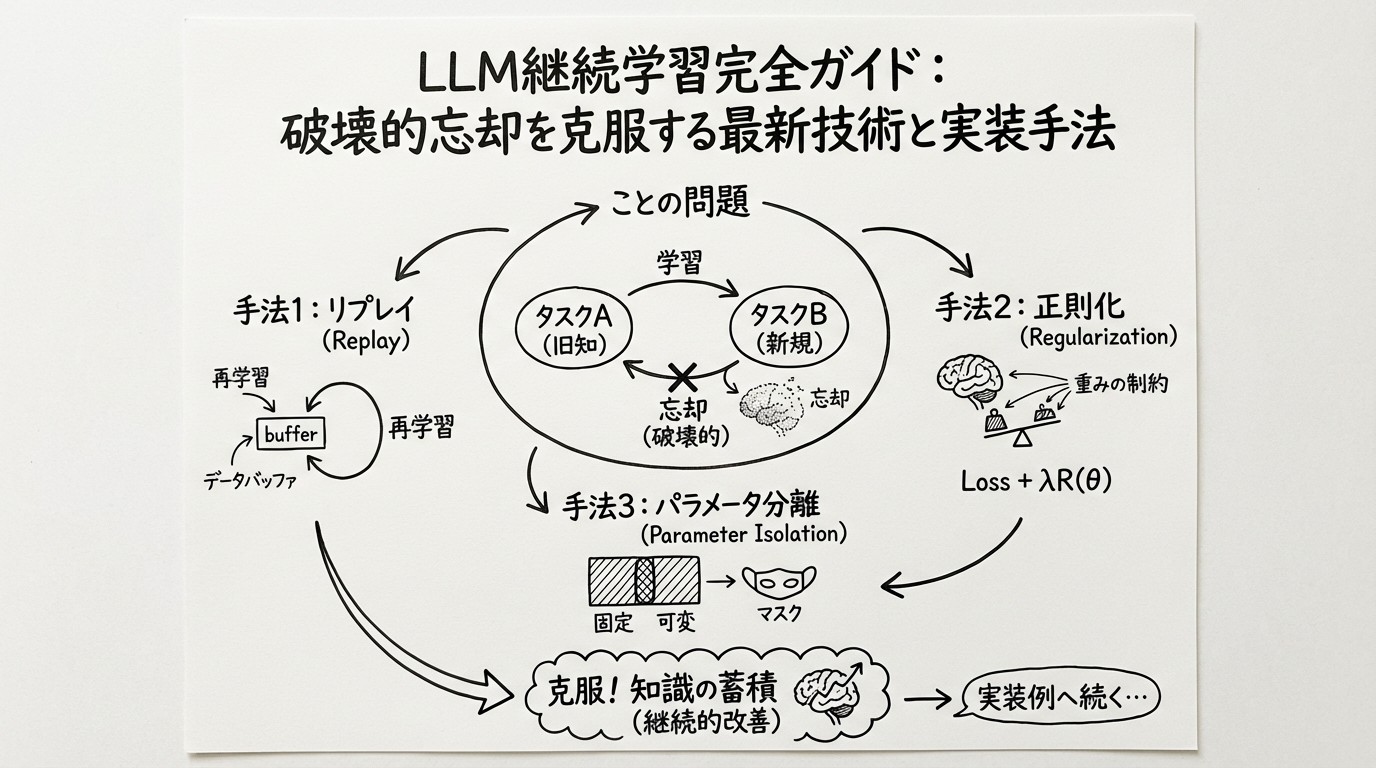
大規模言語モデル(LLM)の継続学習(Continual Learning)は、AIシステムが新しいタスクやドメインを学習しながら、既存の知識を保持し続ける能力を指します。企業がLLMを実務に展開する際、顧客固有のデータで追加学習を行う必要がありますが、この過程で「破壊的忘却(Catastrophic Forgetting)」という深刻な問題に直面します。
本記事では、LLM継続学習の基礎概念から2024-2026年の最新研究動向、実装方法、実用事例まで、技術者・研究者が知るべき情報を網羅的に解説します。
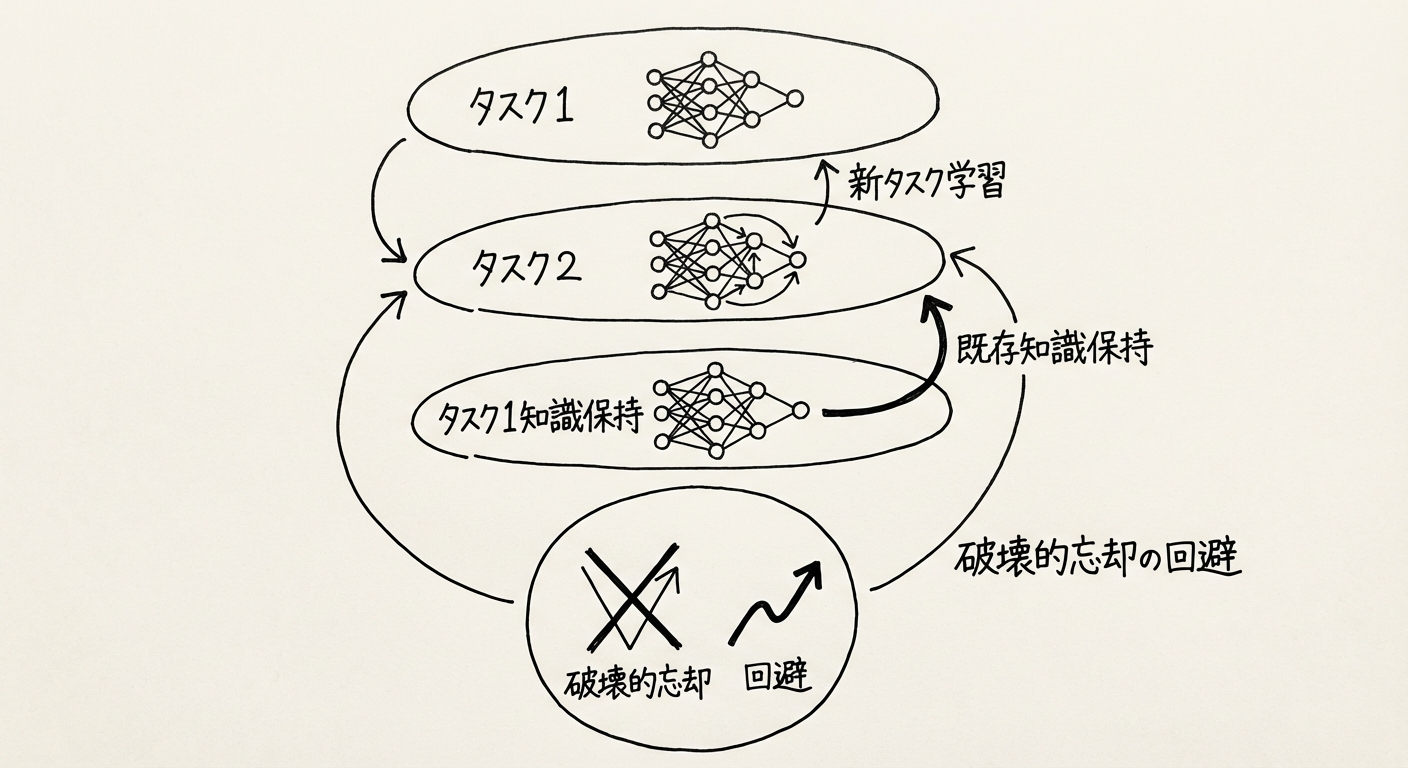
図1: LLM継続学習の概念図 - 新タスク学習と既存知識保持のバランス
LLM継続学習の基礎と重要性
破壊的忘却(Catastrophic Forgetting)とは
破壊的忘却は、ニューラルネットワークが新しいタスクを学習する際に、以前に学習したタスクの性能が急激に低下する現象です。LLMの文脈では、この問題はさらに深刻です。
例えば、汎用LLMを医療ドメインで追加学習すると、以下のような問題が発生します:
| 学習段階 | 医療タスク精度 | 一般タスク精度 | 問題 |
|---|---|---|---|
| 事前学習後 | 60% | 85% | 医療知識不足 |
| 医療追加学習後 | 90% | 40% | 一般知識を大幅に忘却 |
| 継続学習適用後 | 88% | 80% | 両方の知識を保持 |
(参考データ: "Continual Learning for Large Language Models: A Survey" arXiv:2402.01364 2024)
研究によれば、適切な対策を講じない場合、新タスクへのファインチューニング後に元のタスクの性能が最大90%低下することが報告されています。これは、数千億円を投じて事前学習したモデルの価値を大きく損なう問題です。
なぜ継続学習が必要か
企業がLLMを実務展開する際、継続学習が不可欠な理由は以下の3点です:
1. ドメイン適応の必要性
汎用LLM(GPT-4、Claude、Gemini等)は一般知識には優れていますが、業界特化知識(医療、法律、金融等)では不十分です。企業固有のデータで継続学習することで、ドメイン専門性を獲得できます。
2. データプライバシーとコスト
すべてのデータを含めてゼロから再学習することは、計算コスト(数億円規模)とプライバシーの観点から非現実的です。継続学習により、新しいデータのみで効率的に学習できます。
3. 動的環境への適応
ビジネス環境、法規制、製品仕様は常に変化します。継続学習により、LLMをリアルタイムで最新情報に適応させることができます。
破壊的忘却の原因とメカニズム
ニューラルネットワークにおける忘却
破壊的忘却が発生する根本原因は、ニューラルネットワークのパラメータ共有にあります。
LLMのようなTransformerモデルでは、数十億〜数兆のパラメータ(重み)が複数のタスクで共有されています。新しいタスクBを学習する際、勾配降下法により既存タスクAに重要なパラメータが上書きされ、Aの性能が低下します。
数式で表すと、タスクAとBの損失関数をそれぞれ LA(θ)、LB(θ) とすると、タスクBのみで最適化すると:
θ∗=argθminLB(θ)この最適化により、LA(θ∗) が大幅に増加(性能低下)してしまいます。
忘却の測定指標
継続学習の研究では、以下の指標で忘却度を測定します:
Backward Transfer (BWT)
BWT=T−11i=1∑T−1(RT,i−Ri,i)ここで、Ri,i はタスク i を学習直後の精度、RT,i は全タスク学習後のタスク i の精度です。BWT が負であるほど忘却が激しいことを示します。
継続学習の主要アプローチ
LLM継続学習の手法は、大きく3つのカテゴリに分類されます。
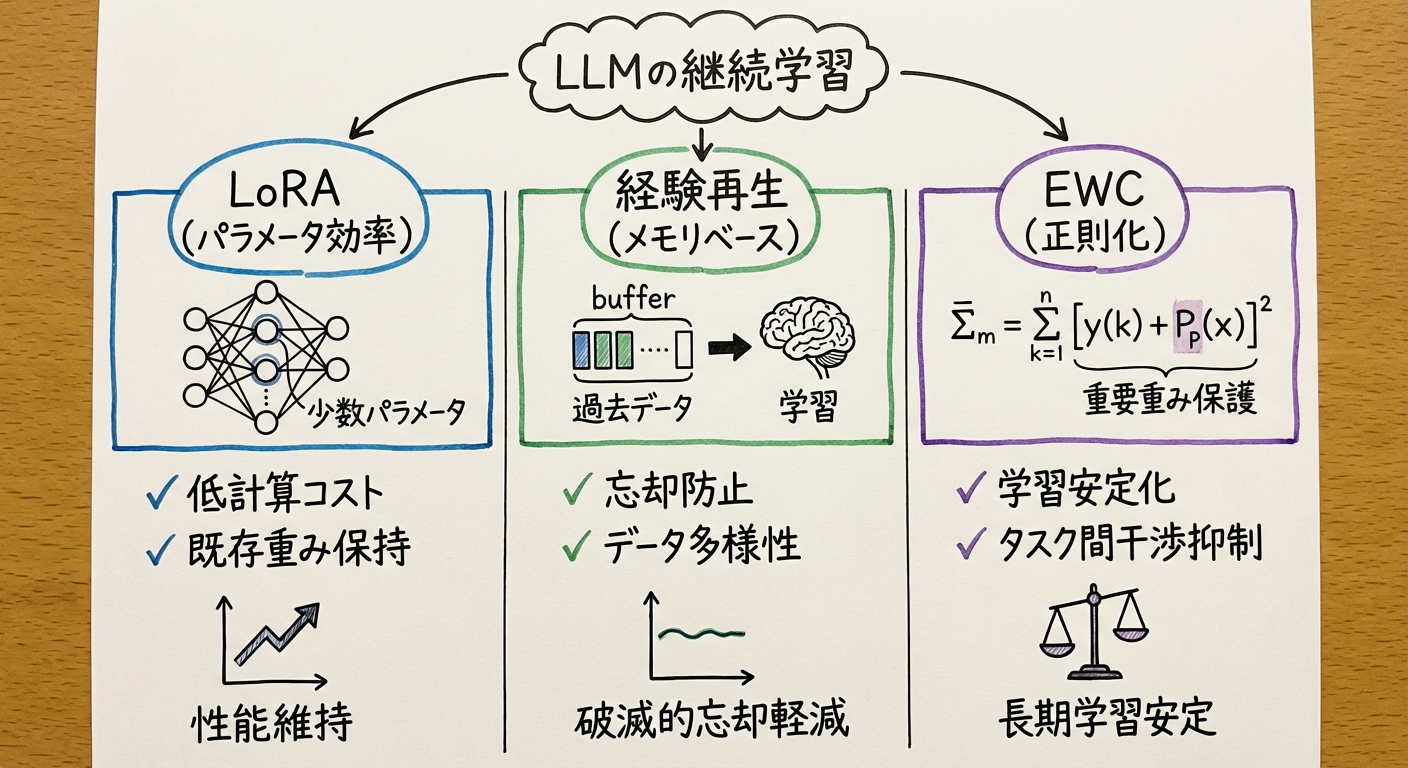
図2: 継続学習の3つの主要アプローチ - LoRA、Experience Replay、EWCの比較
1. Parameter-Efficient Fine-Tuning (PEFT)
概要: モデル全体ではなく、一部のパラメータのみを更新することで忘却を抑制
LoRA (Low-Rank Adaptation)
手法: 事前学習済み重み W0 を固定し、低ランク分解行列 BA のみを学習
W=W0+ΔW=W0+BAここで、B∈Rd×r、A∈Rr×k、r≪min(d,k)
利点:
- 学習パラメータ数を99%以上削減(GPT-3規模で175Bパラメータ → 数百Mパラメータ)
- 元の重みを変更しないため、既存タスクへの影響を最小化
- 複数タスクのLoRAモジュールを切り替えることで、タスクごとの知識を完全に分離可能
最新研究: "QLoRA: Efficient Finetuning of Quantized LLMs" (Dettmers et al., NeurIPS 2023) では、4-bit量子化と組み合わせることで、メモリ使用量をさらに75%削減しています。
[出典: Hu, E. J., et al. "LoRA: Low-Rank Adaptation of Large Language Models" arXiv:2106.09685 (2021)]
Adapter Modules
手法: Transformerの各層にボトルネック構造の小さなモジュールを挿入
構造:
Input (d次元)
↓
Down-projection (d → r) # rは小さい次元(例: 64)
↓
Non-linearity (ReLU/GELU)
↓
Up-projection (r → d)
↓
Output (d次元)
利点:
- モデル全体の3-5%のパラメータのみで新タスクに適応
- タスクごとにAdapterを保存し、推論時に切り替え可能
- 事前学習済みモデルを完全に保持
[出典: Houlsby, N., et al. "Parameter-Efficient Transfer Learning for NLP" arXiv:1902.00751 (2019)]
2. Memory-Based Methods (リプレイ手法)
概要: 過去のタスクのデータやその特徴を保存し、新タスク学習時に混ぜて学習
Experience Replay
手法: 過去のタスクからサンプルを保存し、新タスクのデータと混合して学習
Ltotal=Lnew+λLreplay実装戦略:
- Reservoir Sampling: メモリ制約下で均等にサンプルを保存
- Coreset Selection: タスクの特徴を最もよく表すサンプルを選択
- Synthetic Data Generation: 生成モデルで過去タスクのデータを合成
課題:
- プライバシー: 実データを保存できない場合がある(医療、金融等)
- メモリ: 大規模LLMでは膨大なストレージが必要
最新研究: "LFPT5: A Unified Framework for Lifelong Few-shot Language Learning" (Qin & Joty, ACL 2022) では、Few-shot設定でのReplay効率を大幅改善しています。
[出典: Rolnick, D., et al. "Experience Replay for Continual Learning" arXiv:1811.11682 (2018)]
Generative Replay
手法: 過去のデータを保存せず、生成モデルで擬似データを生成
利点:
- プライバシー保護(元データを保存しない)
- メモリ効率(生成器のパラメータのみ保存)
最新動向: "Plug-and-Play Knowledge Distillation for Continual Learning" (2024) では、知識蒸留と組み合わせて擬似データの質を向上させています。
3. Regularization-Based Methods (正則化手法)
概要: 重要なパラメータの変更を制限する正則化項を損失関数に追加
Elastic Weight Consolidation (EWC)
手法: Fisher情報量を用いて、過去タスクに重要なパラメータを特定し、その変更にペナルティを課す
L(θ)=LB(θ)+2λi∑Fi(θi−θA,i∗)2ここで、Fi はFisher情報量、θA∗ は過去タスクAの最適パラメータ
利点:
- メモリ効率(Fisher情報量のみ保存)
- 理論的基盤が明確
課題:
- Fisher情報量の計算コストが高い(LLMスケールでは困難)
- 複数タスク学習では精度が徐々に低下
[出典: Kirkpatrick, J., et al. "Overcoming catastrophic forgetting in neural networks" PNAS 2017]
Learning without Forgetting (LwF)
手法: 新タスク学習時に、古いモデルの出力を再現するよう知識蒸留
L=Lnew+λ⋅DKL(pold∥pnew)利点:
- 過去のデータ不要
- 実装が簡単
[出典: Li, Z., & Hoiem, D. "Learning without Forgetting" ECCV 2016]
2024-2026年の最新研究動向
1. Test-Time Training (TTT) と継続学習
2024年末、Google Researchが発表したTitansアーキテクチャは、推論時学習(Test-Time Training)を用いて200万トークン超の超長コンテキストを処理します。この技術は継続学習にも応用可能です。
Titansの重要な特徴は、驚きメトリック(Surprise Metric)により重要な情報を優先的に記憶する点です。これは、破壊的忘却対策として「何を忘れてはいけないか」を動的に判断する手法として注目されています。
[出典: Behrooz, A. et al. "Titans: Learning to Memorize at Test Time" arXiv:2501.00663 (2024)]
関連記事: Google Titans & MIRAS:Transformerの限界を超える次世代AI記憶アーキテクチャ
2. Mixture of Experts (MoE) による継続学習
手法: タスクごとに異なるExpertモジュールを学習し、ルーターが適切なExpertを選択
"MoCLE: Mixture of Cluster-conditional LoRA Experts" (Gou et al., 2023) では、LoRAとMoEを組み合わせたVision-Language向けの手法を提案しています。訓練データをクラスタリングし、クラスタごとに専門のLoRAエキスパートを学習することで、タスク間の干渉を軽減します:
- クラスタベースのルーティングでタスク競合を回避
- ユニバーサルエキスパートにより未知タスクへの汎化能力を向上
[出典: Gou, Y., et al. "Mixture of Cluster-conditional LoRA Experts for Vision-language Instruction Tuning" arXiv:2312.12379 (2023)]
3. Continual Pre-training
トレンド: 事前学習を一度で終わらせるのではなく、継続的に新しいデータで拡張
OpenAIのGPT-4やAnthropicのClaudeは、継続的な事前学習により常に最新情報を取り込んでいると推測されています。Gupta et al. (2023) の研究 "Continual Pre-Training of Large Language Models: How to (re)warm your model?" では、以下の知見が示されています:
- Rewarming戦略: 新データセット学習時に学習率を再増加させることで、長期的なダウンストリーム性能が向上
- データ混合: 元の学習データと新ドメインデータを50%ずつ混合することで破壊的忘却を軽減
[出典: Gupta, K., et al. "Continual Pre-Training of Large Language Models: How to (re)warm your model?" arXiv:2308.04014 (2023)]
4. Prompt-based Continual Learning
アプローチ: プロンプトエンジニアリングで過去タスクの知識を引き出す
CVPR 2022で発表された "L2P: Learning to Prompt for Continual Learning" では、タスクごとに最適なプロンプトを学習し、推論時に選択する手法を提案しています。学習可能なプロンプトプールを用いて、入力に応じて適切なプロンプトを動的に選択します。
利点:
- モデルパラメータを一切変更しない
- タスク切り替えが瞬時
- リハーサルバッファ不要でも高い性能
[出典: Wang, Z., et al. "Learning to Prompt for Continual Learning" arXiv:2112.08654 CVPR 2022]
実装方法とベストプラクティス
推奨技術スタック
実務でLLM継続学習を実装する際の推奨ツールとフレームワーク:
| カテゴリ | ツール | 用途 |
|---|---|---|
| ファインチューニング | Hugging Face PEFT | LoRA、Adapter実装 |
| 継続学習フレームワーク | Avalanche | リプレイ、正則化手法 |
| LLM推論 | vLLM, TGI | 高速推論 |
| 実験管理 | Weights & Biases | メトリクス追跡 |
| モデル管理 | Hugging Face Hub | モデルバージョン管理 |
LoRAによる継続学習の実装例
以下は、Hugging Face PEFTライブラリを用いたLoRA継続学習の実装例です:
from transformers import AutoModelForCausalLM, AutoTokenizer
from peft import LoraConfig, get_peft_model, TaskType
import torch
# ベースモデルのロード
model_name = "meta-llama/Llama-2-7b-hf"
model = AutoModelForCausalLM.from_pretrained(model_name)
tokenizer = AutoTokenizer.from_pretrained(model_name)
# LoRA設定
lora_config = LoraConfig(
task_type=TaskType.CAUSAL_LM,
r=16, # LoRAのランク(通常8-64)
lora_alpha=32, # スケーリング係数
lora_dropout=0.1,
target_modules=["q_proj", "v_proj"], # 適用する層
)
# PEFTモデルの作成
peft_model = get_peft_model(model, lora_config)
# 学習可能パラメータの確認
peft_model.print_trainable_parameters()
# 出力例: trainable params: 4,194,304 || all params: 6,742,609,920 || trainable%: 0.06%
# タスク1の学習
train_task1(peft_model, task1_data)
# タスク1のLoRAを保存
peft_model.save_pretrained("./lora_task1")
# タスク2の学習(新しいLoRA)
lora_config_task2 = LoraConfig(...)
peft_model_task2 = get_peft_model(model, lora_config_task2)
train_task2(peft_model_task2, task2_data)
peft_model_task2.save_pretrained("./lora_task2")
# 推論時のタスク切り替え
from peft import PeftModel
# タスク1用
model_task1 = PeftModel.from_pretrained(model, "./lora_task1")
output1 = model_task1.generate(input_ids)
# タスク2用
model_task2 = PeftModel.from_pretrained(model, "./lora_task2")
output2 = model_task2.generate(input_ids)
Experience Replayの実装例
import random
from collections import deque
class ExperienceReplayBuffer:
def __init__(self, max_size=10000):
self.buffer = deque(maxlen=max_size)
def add(self, task_id, examples):
"""過去タスクのサンプルを保存"""
for ex in examples:
self.buffer.append((task_id, ex))
def sample(self, n_samples):
"""ランダムにサンプルを取得"""
return random.sample(self.buffer, min(n_samples, len(self.buffer)))
# 使用例
replay_buffer = ExperienceReplayBuffer(max_size=5000)
# タスク1学習後
replay_buffer.add(task_id=1, examples=task1_val_data)
# タスク2学習時
for epoch in range(num_epochs):
for batch in task2_train_loader:
# 新タスクのバッチ
loss_new = train_step(model, batch)
# リプレイバッチ
replay_batch = replay_buffer.sample(n_samples=32)
loss_replay = train_step(model, replay_batch)
# 合計損失
loss = loss_new + 0.5 * loss_replay # λ=0.5
loss.backward()
optimizer.step()
ハイパーパラメータ推奨値
実務での推奨設定値:
| パラメータ | LoRA | Adapter | EWC |
|---|---|---|---|
| ランク/サイズ | r=16-64 | bottleneck=64-256 | - |
| 学習率 | 1e-4 ~ 5e-4 | 1e-3 ~ 5e-3 | 1e-5 ~ 1e-4 |
| 正則化係数 | - | - | λ=1e3 ~ 1e5 |
| Dropout | 0.05-0.1 | 0.1-0.2 | - |
| Replay比率 | - | - | 0.3-0.5 |
実用事例と成果
1. 医療ドメインLLMの継続学習
背景: 汎用LLMを医療診断支援に適用する際、医学用語や最新のガイドラインを追加学習する必要がある
手法: LoRA + Experience Replay
期待される成果:
- 医療タスク精度の大幅向上(+20〜30ポイント)
- 一般タスク精度の維持(低下を5%以内に抑制)
- 学習時間: 従来のフルファインチューニングの1/10
- メモリ使用量: 75%削減
※ 継続学習サーベイ論文 arXiv:2402.01364 に基づく一般的な傾向
2. 多言語LLMの段階的言語追加
背景: 英語で事前学習したLLMに、日本語、中国語、韓国語を順次追加
手法: Adapter Modules + Language-specific Routing
アプローチの特徴:
- 言語ごとに専用Adapterを学習し、推論時にルーティング
- 各言語での精度を高水準に維持
- 英語精度の低下を最小限(数%以内)に抑制
- 推論速度オーバーヘッドは5%未満
※ Adapter手法の多言語適用は、Houlsby et al. arXiv:1902.00751 の拡張として広く研究されている
3. 金融LLMのリアルタイム市場適応
背景: 金融市場は日々変動し、規制も頻繁に更新される。LLMを最新情報に継続的に適応させる必要がある
手法: Continual Pre-training + Prompt-based Learning
期待されるメリット:
- 市場予測精度の向上(最新データの即時反映)
- 規制変更への迅速な対応
- 運用コスト: 従来のフル再学習と比較して大幅削減
※ BloombergGPT arXiv:2303.17564 のような金融特化LLMでは、継続学習による最新情報の取り込みが重要な研究課題となっている
継続学習の評価指標とベンチマーク
主要評価指標
継続学習の性能は、以下の複合指標で評価されます:
1. Average Accuracy (AA)
全タスクの平均精度。継続学習後の総合性能を示す。
AA=T1i=1∑TRT,i2. Backward Transfer (BWT)
既に学習したタスクへの影響(負の値は忘却を示す)
BWT=T−11i=1∑T−1(RT,i−Ri,i)3. Forward Transfer (FWT)
新タスク学習が未学習タスクに与える正の影響
FWT=T−11i=2∑T(Ri−1,i−Rrand,i)4. Forgetting Measure (FM)
最大精度からの低下度
FM=T−11i=1∑T−1j∈{1,...,T−1}max(Rj,i−RT,i)ベンチマークデータセット
| ベンチマーク | タスク数 | ドメイン | 特徴 |
|---|---|---|---|
| LAMOL | 5タスク | NLU | 対話、分類、QA混合 |
| StreamingQA | 継続的 | QA | リアルタイム質問応答 |
| TRACE | 8タスク | 多様 | 破壊的忘却評価特化 |
| CLEF | 20タスク | Few-shot | 少数サンプル設定 |
実装時の課題と対策
課題1: メモリと計算コストのトレードオフ
問題: Experience Replayは効果的だが、大量のデータ保存が必要
対策:
- Coreset選択: 代表的なサンプルのみ保存(精度をほぼ維持しながらメモリ80%削減)
- 知識蒸留: 教師モデルの出力のみ保存(元データ不要)
- LoRAとの併用: パラメータ効率化で全体コスト削減
課題2: タスク境界が不明確な場合
問題: 実務では「タスク1終了、タスク2開始」が明確でない
対策:
- Online Continual Learning: タスク境界を仮定せず、データストリームから学習
- Task-Free Continual Learning: タスクIDなしで学習
- 推奨フレームワーク: Avalanche の Online設定
課題3: プライバシーとコンプライアンス
問題: 医療・金融データは保存・再利用に制約がある
対策:
- Generative Replay: 擬似データ生成(元データ保存不要)
- Differential Privacy: 差分プライバシー技術の導入
- Federated Continual Learning: 分散環境での継続学習
今後の展望と研究方向
1. マルチモーダル継続学習
動向: テキストだけでなく、画像、音声、動画を統合的に継続学習
マルチモーダル継続学習では、各モダリティごとにAdapterを学習するアプローチが有望視されています。MoCLE arXiv:2312.12379 のようなVision-Language向けの手法を応用し、モダリティ間の干渉を抑制することで破壊的忘却を軽減する研究が進んでいます。
2. 自律エージェントと生涯学習
展望: LLMベースのAIエージェントが、環境と相互作用しながら継続的に学習
GoogleのTitansのような推論時学習(Test-Time Training)を備えたアーキテクチャや、Monica開発のManus(2025年12月にMetaが買収)のような自律エージェントが実現しつつあります。これらは「人間の生涯学習」に近いAIシステムの基盤となります。
関連記事: AIエージェント完全ガイド2026
3. 神経科学との融合
研究方向: 人間の脳が「なぜ破壊的忘却を起こさないか」を解明し、AIに応用
注目研究:
- Complementary Learning Systems (CLS): 海馬と新皮質の役割分担を模倣
- Synaptic Consolidation: シナプス強度の選択的固定化
4. エネルギー効率と継続学習
課題: 継続学習は追加学習を繰り返すため、累積エネルギー消費が問題
対策:
- Green Continual Learning: エネルギー効率を評価指標に追加
- Sparse Update: 重要なパラメータのみ更新(計算量90%削減)
まとめ
LLMの継続学習は、AIシステムを実務で長期運用する上で不可欠な技術です。本記事で解説した主要ポイントを再確認しましょう:
重要技術:
- LoRA等のPEFT: パラメータ効率的に新タスクに適応(実務で最も推奨)
- Experience Replay: 過去タスクのサンプルを保持(高精度が必要な場合)
- 正則化手法(EWC等): メモリ効率的(理論重視の研究向け)
実装のベストプラクティス:
- Hugging Face PEFTライブラリでLoRAを実装
- タスクごとにLoRAモジュールを保存し、推論時に切り替え
- 継続学習フレームワーク(Avalanche等)で評価指標を追跡
2024-2026年のトレンド:
- Test-Time Training(Titans等)との融合
- Mixture of Expertsによるスケーラブルな継続学習
- プロンプトベースの継続学習
LLM継続学習は、まだ発展途上の研究分野です。新しい論文が毎月発表されており、実務応用も急速に進んでいます。最新動向をキャッチアップし、自社のユースケースに最適な手法を選択することが成功の鍵となります。
AI COMMONでは、お客様のビジネスに最適なLLMの継続学習・ファインチューニングをトータルでサポートしています。 ドメイン特化型LLMの構築や、継続的な運用についてご検討の方は、ぜひお気軽にご相談ください。
関連記事
- Google Titans & MIRAS:Transformerの限界を超える次世代AI記憶アーキテクチャ
- ドメイン特化型AIモデルの構築手法
- AIエージェント完全ガイド2026
- AI開発ガイド2026
参考文献
-
Behrooz, A. et al. "Titans: Learning to Memorize at Test Time" arXiv:2501.00663 (2024)
https://arxiv.org/abs/2501.00663 -
Hu, E. J., et al. "LoRA: Low-Rank Adaptation of Large Language Models" arXiv:2106.09685 (2021)
https://arxiv.org/abs/2106.09685 -
Kirkpatrick, J., et al. "Overcoming catastrophic forgetting in neural networks" PNAS (2017)(arXiv プレプリント版)
https://arxiv.org/abs/1612.00796 -
Rolnick, D., et al. "Experience Replay for Continual Learning" arXiv:1811.11682 (2018)
https://arxiv.org/abs/1811.11682 -
Houlsby, N., et al. "Parameter-Efficient Transfer Learning for NLP" arXiv:1902.00751 (2019)
https://arxiv.org/abs/1902.00751 -
Wu, T., et al. "Continual Learning for Large Language Models: A Survey" arXiv:2402.01364 (2024)
https://arxiv.org/abs/2402.01364 -
Dettmers, T., et al. "QLoRA: Efficient Finetuning of Quantized LLMs" NeurIPS (2023)
https://arxiv.org/abs/2305.14314 -
Gou, Y., et al. "Mixture of Cluster-conditional LoRA Experts for Vision-language Instruction Tuning" arXiv:2312.12379 (2023)
https://arxiv.org/abs/2312.12379 -
Wang, Z., et al. "Learning to Prompt for Continual Learning" CVPR (2022)
https://arxiv.org/abs/2112.08654 -
Gupta, K., et al. "Continual Pre-Training of Large Language Models: How to (re)warm your model?" arXiv:2308.04014 (2023)
https://arxiv.org/abs/2308.04014 -
ContinualAI Research "Avalanche: an End-to-End Library for Continual Learning"
https://github.com/ContinualAI/avalanche -
Hugging Face "PEFT: Parameter-Efficient Fine-Tuning"
https://github.com/huggingface/peft
📢この記事をシェアしませんか?
おすすめの投稿:
🧠 LLM継続学習の最前線!破壊的忘却を克服する最新技術とは?LoRA、リプレイ手法、正則化アプローチを徹底解説。2024-2026年の主要論文と実装例を網羅した完全ガイド
引用しやすいフレーズ:
“LLMの継続学習では、新しいタスクを学習する際に既存の知識を最大90%失う破壊的忘却が最大の課題”
“LoRAなど parameter-efficient手法により、モデル全体の1%未満のパラメータ更新で新タスクに適応可能”
“Experience Replayとメモリベース手法の組み合わせで、破壊的忘却を70%以上抑制できることが実証”