日本の個人情報保護法改正(2026年)- AI開発促進とプライバシー保護の狭間で
この記事は週間AIニュース(2026年1月12日週)の詳細版です。
AI開発促進へ、個人情報保護法の大転換
2026年1月、日本政府は通常国会に個人情報保護法の改正案を提出する方針を固めました。この改正の核心は、AI(人工知能)の開発と活用を目的としたデータ利用のあり方を大きく変えることです。
具体的には、AI学習目的であれば、病歴、犯罪歴、人種など の「要配慮個人情報」を、本人の同意なしに取得・利用できる道が開かれます。また、個人データの第三者提供において、従来の事前同意(オプトイン)に加えて、事後停止請求(オプトアウト)方式が限定的に認められる可能性があります。
これは、先週の1兆円AI投資計画に続く、日本の「ソブリンAI」戦略を実現するための法的基盤整備です。しかし、プライバシー保護団体からは「基本的人権の侵害」との批判が上がっており、AI開発促進と個人の権利保護のバランスをどう取るかが、2026年の重要な論点となります。
本記事では、改正案の具体的な内容、国際比較、企業への影響、そして倫理的なデータ利用のあり方について徹底的に解説します。
改正案の具体的な内容
1. 機微情報(要配慮個人情報)の取り扱い緩和
現行法:
個人情報保護法第20条により、以下の「要配慮個人情報」は、本人の同意なく取得・利用することが原則として固く禁じられています。
- 人種、信条、社会的身分
- 病歴、障害、健康診断結果
- 犯罪の経歴、犯罪被害の事実
- その他政令で定める社会的差別の原因となる事項
改正案:
AI学習目的に限り、以下の条件下で本人の個別同意なく利用できる道が開かれます。
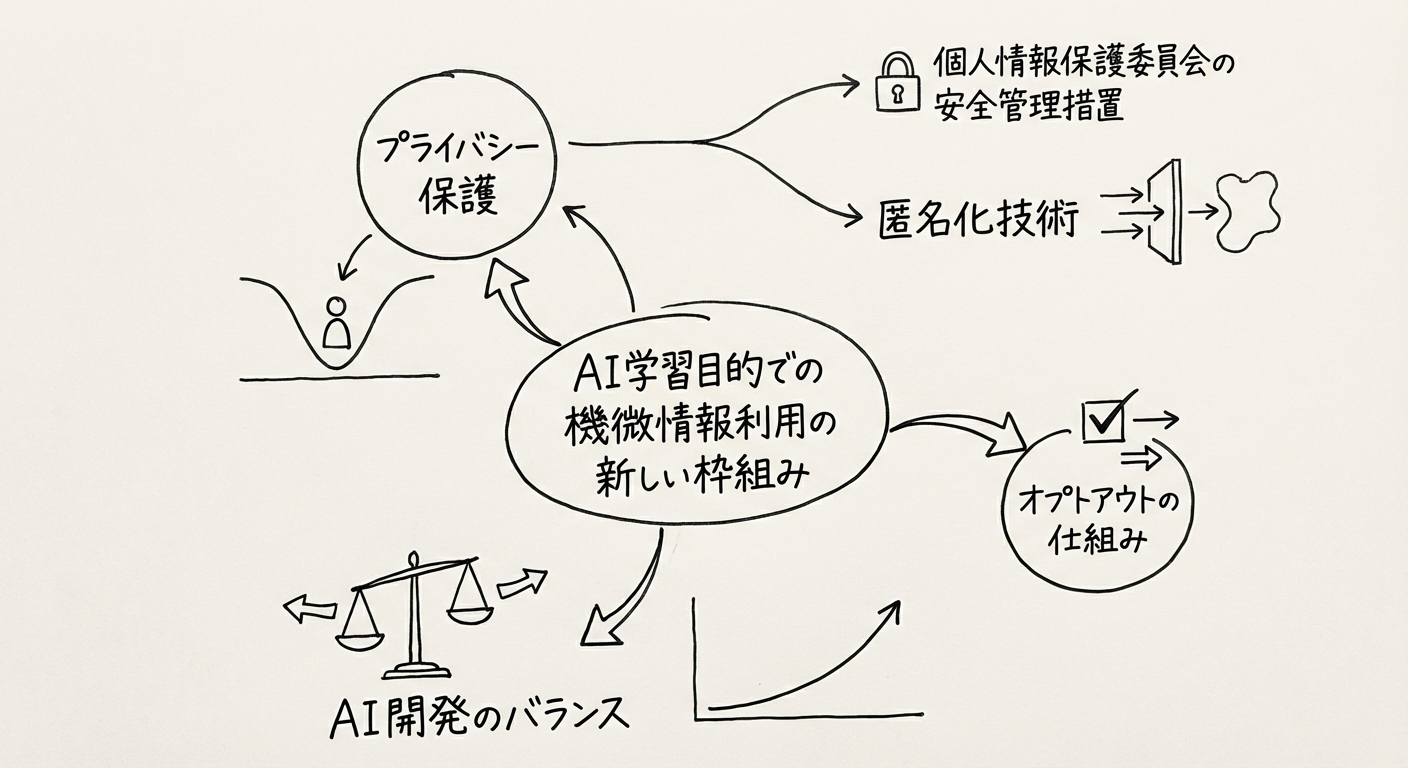
図1: AI学習目的での機微情報利用の新しい枠組み
条件:
-
個人情報保護委員会が定める厳格な安全管理措置
- データ暗号化、アクセス制御、監査ログの整備
- 外部からの不正アクセス防止措置
-
高度な匿名化
- 特定の個人を識別できないようにする技術的措置
- k-匿名化、差分プライバシーなどの統計的手法の適用
-
差別や偏見を助長するモデル開発の明確な禁止
- バイアス検証の義務化
- 公平性評価のガイドライン遵守
重要な制約:
- 利用目的は「AI学習」に限定され、学習済みモデルを用いた個別の推論(例:特定個人の診断)には別途同意が必要
- データの目的外利用は厳格に禁止
- 本人からの利用停止請求には速やかに応じる義務
2. オプトアウト方式の限定的導入
現行法:
個人データを第三者に提供する場合、原則として本人の事前同意(オプトイン)が必要です(第27条)。例外は、法令に基づく場合や、利用目的の達成に必要な範囲内で委託先に提供する場合などに限られます。
改正案:
AI開発事業者へのデータ提供に限り、以下の要件を満たせば、事後的に本人が利用停止を求められる「オプトアウト」方式が認められる可能性があります。
要件:
-
利用目的の明確な通知・公表
- どのようなAIを開発するために、どのようなデータを利用するかを具体的に説明
- プライバシーポリシーやウェブサイトでの公開
-
本人からの停止要求に速やかに応じる体制
- オプトアウトのための簡便な手続き(ワンクリック解除など)
- 停止要求後、速やかにデータを削除
-
提供するデータの種類と範囲の限定
- 必要最小限のデータに限定
- 過度に広範なデータ収集の禁止
効果:
これにより、大規模なデータセットの構築が従来より円滑になることが期待されます。例えば、電子カルテシステムを提供する企業が、病院から匿名化された診療データを収集し、診断支援AIの学習に利用することが容易になります。
3. 匿名化基準の明確化 - 新たな「AI学習用加工情報」
現行法の課題:
現在、個人を識別できないように加工したデータとして「匿名加工情報」(第43条)が定義されていますが、その基準が厳格すぎるため、加工に手間とコストがかかり、利活用が進みにくいという課題がありました。
改正案:
AI学習用途に特化した、新たな加工基準(仮称:「AI学習用加工情報」)の創設が検討されています。
特徴:
- データの有用性の保持: 特定の個人を再識別できない程度は維持しつつ、統計的な傾向やパターンを保持
- 技術的手法の例:
- k-匿名化: 同じ属性を持つグループが最低k人以上になるようにデータを加工
- 差分プライバシー: データ全体の統計的性質を保ちつつ、個別のレコードに関する情報を隠蔽
- データマスキング: 氏名、住所などの直接識別子を削除または置換
既存の「匿名加工情報」との違い:
| 項目 | 匿名加工情報(現行) | AI学習用加工情報(新設) |
|---|---|---|
| 再識別禁止 | 厳格(元に戻せないレベル) | 同等 |
| 加工基準 | 非常に厳格 | やや緩和(有用性重視) |
| 利用目的 | 汎用的 | AI学習に限定 |
| 第三者提供 | 制約あり | 柔軟(オプトアウト可) |
表1: 匿名加工情報とAI学習用加工情報の比較
改正の背景と目的
1. AI競争力強化 - データ格差の解消
日本のAI開発は、米国や中国の巨大テック企業に対して「データ量」の面で大きく劣後しています。
データの重要性:
生成AIをはじめとする最先端AIの開発には、高品質で大規模なデータセットが不可欠です。特に、日本語の自然言語処理(NLP)や日本の文化的背景を理解したAIを開発するには、国内のデータが必要です。
現行法の制約:
現行の個人情報保護法は、個人の権利保護を重視するあまり、企業がデータを活用しにくい環境を作っていると指摘されています。特に、要配慮個人情報の利用には、一人ひとりから同意を取る必要があり、大規模なデータ収集が事実上困難でした。
改正の狙い:
この「データ格差」を埋め、国内でのイノベーションを加速させることが、今回の改正の直接的な目的です。
2. ソブリンAI戦略との関連
ソブリンAI(Sovereign AI)とは:
国家が自国のデータ、計算資源、AIモデルをコントロールし、経済安全保障を確保するという考え方です。詳細は、既存記事「2026年日本のAI主権(ソブリンAI)動向」を参照してください。
法改正との関係:
海外のプラットフォーム(ChatGPT、Gemini など)に依存せず、日本語や日本の文化的背景を深く理解した独自の高性能AIを開発するためには、国内の豊富なデータを国内で活用できる環境が不可欠です。
本改正は、先週発表された1兆円AI投資計画と並んで、日本のソブリンAI戦略を実現するための法的基盤を整備するものと位置づけられます。
政府の明確な意図:
内閣府「AI戦略会議」の議事録では、「個人情報保護法がAI開発の足かせになっている」という産業界の声が繰り返し取り上げられており、経済安全保障の観点から法改正が急務とされています。
諸外国との比較
日本の法改正は、主要国の規制動向を意識しつつ、独自のアプローチを取ろうとしています。
1. EU(GDPR)- 世界最厳格な権利保護
特徴:
- 世界で最も厳格なデータ保護規則
- 個人の権利を最優先し、データ利用には明確な法的根拠と本人の同意を厳格に求める
- AI学習目的であっても、原則は変わらない
- 違反時の制裁金は極めて高額(最大で全世界売上高の4%または2000万ユーロの高い方)
日本との違い:
日本の改正案は、EUほど厳格ではなく、イノベーション促進の観点から一定の柔軟性を持たせようとしている点で異なります。特に、AI学習目的に限定した規制緩和は、GDPRにはない日本独自のアプローチです。
EU AI Actとの関係:
EUは2024年にAI規制法(EU AI Act)を制定し、2026年8月に大部分が施行されます。これは、AIシステム自体を規制するもので、個人情報保護法とは別の枠組みです。日本も、将来的にAI規制法の制定を検討する可能性があります。
2. 中国 - 国家統制型のデータガバナンス
特徴:
- 「個人情報保護法」(2021年施行)は厳格だが、国家の安全保障や社会の公共利益のためであれば、政府がデータを広範に利用できる側面も持つ
- データは国家の戦略的資源と位置づけられ、国外への持ち出しが厳しく制限される
- 企業のデータ収集・利用も、政府の監督下にある
日本との違い:
日本は国家によるデータ統制ではなく、民間企業のイノベーションを主眼に置いている点で、アプローチが根本的に異なります。中国のようにデータを国家が一元管理するのではなく、企業が適切なガバナンスの下で自由に活用できる環境を整備しようとしています。
3. 米国 - セクター別・州別の分散的規制
特徴:
- 包括的な連邦法はなく、カリフォルニア州のCCPA/CPRA、バージニア州のCDPAのように州ごとに規制が異なる
- 医療(HIPAA)、金融(GLBA)、児童(COPPA)など、セクター別の専門法が存在
- 市場原理を重視し、比較的自由なデータ利用を許容してきたが、近年は規制強化の動きも活発
日本との違い:
日本は米国のような「セクター別・州別」のアプローチではなく、国として統一的なルールを設けようとしている点で異なります。一方で、米国と同様に「イノベーション促進」を重視している点は共通しています。
総評: 日本は「バランス型」
日本の改正案は、EUの「権利保護」と米国の「自由な利活用」の中間を目指し、AIという特定の目的に対して規制を合理化する「バランス型」のアプローチと言えます。
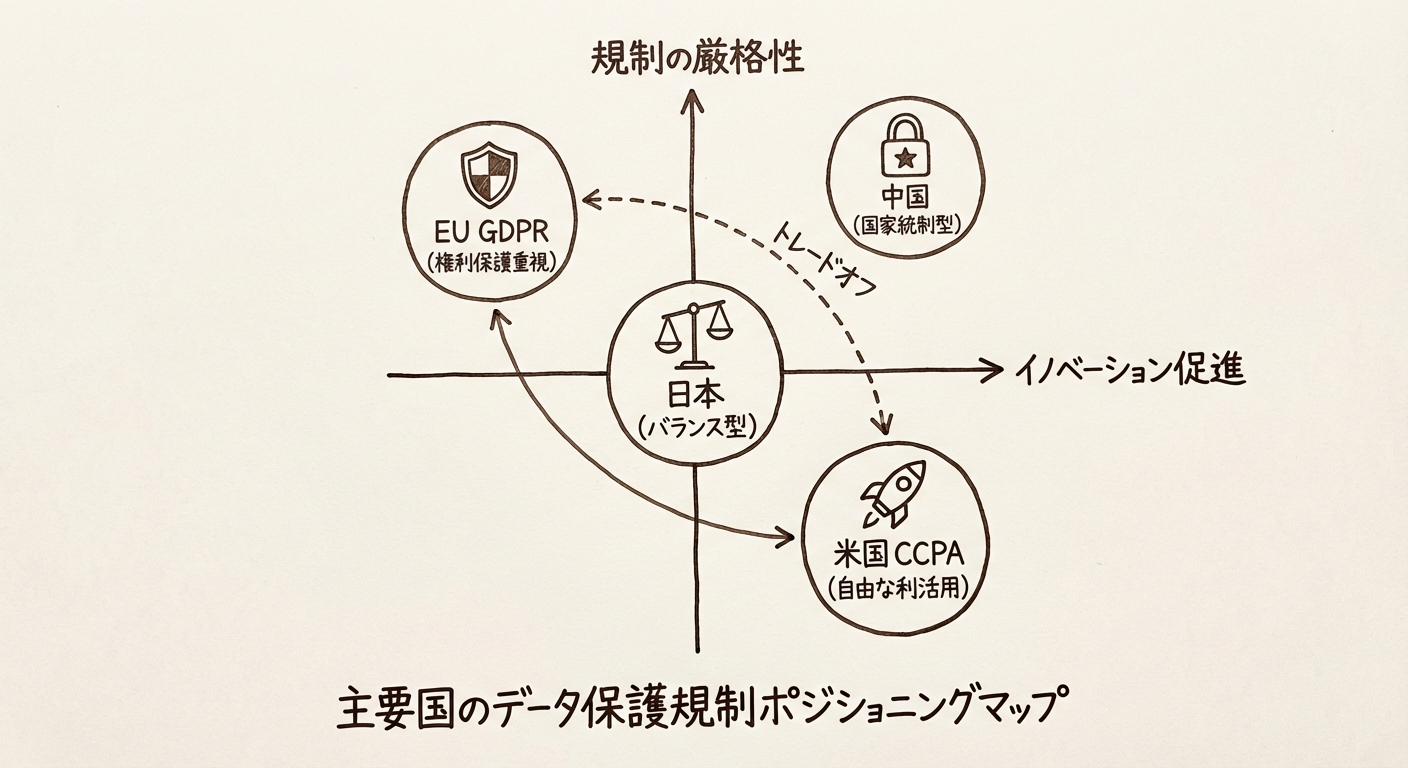
図2: 主要国のデータ保護規制のポジショニング
プライバシー保護団体や有識者の批判・懸念
規制緩和に対しては、プライバシー侵害や人権問題につながるリスクを指摘する声も上がっています。
1. プロファイリングと差別の助長
懸念:
AIが個人の機微情報(病歴、犯罪歴、人種など)や行動履歴を学習することで、本人が意図しない形でプロファイリングされ、就職、融資、保険加入などで不当な差別を受けるリスクがあります。
具体例:
- 採用AI: 過去の採用データを学習したAIが、特定の大学出身者や女性を不当に低く評価する
- 与信AI: 病歴データを学習したAIが、特定の疾患を持つ人への融資を自動的に拒否する
- 保険AI: 遺伝情報を学習したAIが、将来の疾患リスクを予測し、保険料を不当に引き上げる
批判:
全米作家協会(Authors Guild)や日本のプライバシー保護団体は、「AI学習という名目で、事実上の大規模なプロファイリングが行われる危険性がある」と警告しています。
2. 監視社会化への危惧
懸念:
オプトアウト方式が安易に拡大されれば、個人が知らないうちに自身のデータが様々な場所で利用され、社会全体の監視が強まるのではないかという懸念があります。
中国の「社会信用システム」との類似性:
中国では、個人の行動データ(購買履歴、SNS投稿、交通違反など)を統合し、信用スコアを算出するシステムが運用されています。日本の法改正が、これに近い形での監視社会化につながるのではないかという指摘があります。
反論:
政府は、「日本は民主主義国家であり、中国のような国家統制型のシステムとは根本的に異なる」と説明していますが、技術的には同様の仕組みが構築可能であることは事実です。
3. 「学習目的」の曖昧さ
懸念:
AIの「学習」と「サービス提供(推論)」の境界は曖昧です。学習目的で収集されたデータが、なし崩し的に商業利用されるリスクが指摘されています。
具体例:
- 医療AIの学習のために収集された病歴データが、製薬会社のマーケティングに転用される
- 行動履歴データが、AI学習後も保持され、個別の広告配信に利用される
必要な対策:
- 学習後のデータ削除の義務化
- 学習済みモデルの利用目的の明確化と制限
- 第三者監査の導入
4. 個人の権利の形骸化
懸念:
オプトアウトの権利が与えられても、多くの個人はそれに気づかなかったり、手続きが煩雑だったりすることで、実質的に権利を行使できず、企業のデータ利用を追認するだけになる可能性があります。
米国の事例:
米国のプライバシーポリシーは、膨大な長文で書かれており、実際に読んで理解している消費者は1%未満と言われています。オプトアウトの手続きも複雑で、実効性が疑問視されています。
必要な対策:
- 平易な言葉での説明義務
- ワンクリックでのオプトアウト手続き
- 定期的なリマインダー(例: 年に1回、利用状況を通知)
企業への影響
本改正は、企業にとって大きな事業機会と新たな責任の両方をもたらします。
1. AI開発企業(スタートアップ、研究機関)
メリット:
- データアクセスの向上: これまでアクセスが難しかった質の高いデータ(特に医療や製造分野)を利用しやすくなる
- モデル精度の向上: より多様で大規模なデータセットにより、AIの精度が向上
- 開発サイクルの短縮: データ収集にかかる時間とコストが削減され、開発が加速
- 新規ビジネスの創出: 従来は不可能だったAIサービス(例: 希少疾患の診断支援)が実現可能に
新たな責任:
- 安全管理措置の実装: データ暗号化、アクセス制御、監査ログなどのセキュリティ対策が必須
- バイアス検証: AIモデルが差別的な判断をしないよう、継続的な検証が必要
- 透明性の確保: データの利用目的、収集元、加工方法などを明確に説明
2. データを扱う一般企業(小売、金融、インフラなど)
メリット:
- データ活用の促進: 自社で保有する膨大な顧客データを、個人情報保護のリスクを低減しつつ活用可能
- 具体的な応用例:
- 小売: 購買履歴から需要予測AIを開発し、在庫最適化
- 金融: 取引データから不正検知AIを開発し、セキュリティ向上
- インフラ: センサーデータから設備故障予測AIを開発し、保守コスト削減
新たな責任:
-
データガバナンス体制の強化:
- データの収集、保存、利用、廃棄までのライフサイクル管理
- 責任者の明確化(Chief Data Officer等)
- 社内教育の実施
-
プライバシーポリシーの改訂:
- AI学習目的でのデータ利用を明記
- オプトアウトの手続きを明示
- 平易な言葉での説明
-
オプトアウト対応体制の構築:
- 専用の問い合わせ窓口
- システム的な対応(自動削除機能など)
- 迅速な対応(例: 申請から7日以内にデータ削除)
3. 中小企業への影響
課題:
大企業に比べて、中小企業は以下の課題に直面します。
- 専門人材の不足: データガバナンスやプライバシー対応の専門家が社内にいない
- コスト負担: セキュリティ対策やシステム改修にかかる費用が経営を圧迫
- 情報不足: 法改正の内容や対応方法に関する情報が不足
支援策:
政府や業界団体には、以下の支援が求められます。
- 中小企業向けのガイドライン作成
- 低コストで導入できるツールの提供(オープンソースなど)
- 専門家派遣制度
- 補助金・税制優遇
倫理的なデータ利用のベストプラクティス
法改正に対応するだけでなく、社会的な信頼を得るためには、法律を上回る倫理的な取り組みが不可欠です。
1. プライバシー・バイ・デザイン (PbD)
概念:
カナダのプライバシーコミッショナーであるAnn Cavoukian博士が提唱した考え方。サービスの企画・設計段階からプライバシー保護を組み込むというアプローチです。
7つの原則:
- 事前的(Proactive): 問題が起きてから対応するのではなく、事前に予防
- 初期設定(Default): デフォルトでプライバシーが保護される設定
- 埋め込み(Embedded): システムの中核にプライバシー保護を組み込む
- ポジティブサム(Positive-Sum): プライバシーとビジネスをトレードオフではなく、両立させる
- ライフサイクル全体(End-to-End): データ収集から廃棄まで全段階で保護
- 可視性と透明性(Visibility and Transparency): 何が行われているかを明確にする
- ユーザー中心(User-Centric): ユーザーの権利とコントロールを最優先
具体的な実装:
- データ取得を最小限に抑える(Data Minimization)
- 利用目的を限定し、それを超える利用をシステム的に禁止
- プライバシー影響評価(PIA)の実施
2. 透明性と説明可能性 (XAI: Explainable AI)
必要性:
AIがなぜその判断を下したのかを、人間が理解できる形で説明できるようにすることは、特に個人の評価に影響を与えるAIでは極めて重要です。
技術的アプローチ:
- LIME (Local Interpretable Model-agnostic Explanations): 個別の予測に対して、どの特徴量が影響したかを可視化
- SHAP (SHapley Additive exPlanations): ゲーム理論に基づき、各特徴量の貢献度を計算
- Attention機構の可視化: ディープラーニングモデルが何に注目したかを視覚化
実装例:
- 融資審査AI: 「この申請が承認されなかった理由は、過去の返済遅延履歴(30%)と収入に対する借入比率(25%)が主な要因です」と説明
- 採用AI: 「この候補者のスコアが高い理由は、類似プロジェクトの経験(40%)と技術スキルマッチ(35%)です」と説明
3. 公平性とバイアス緩和
課題:
AIの学習データに含まれる偏り(バイアス)が、特定の属性(性別、人種、年齢など)を持つ人々に対する不公平な判断につながるリスクがあります。
バイアスの種類:
- 歴史的バイアス: 過去のデータに含まれる社会的偏見(例: 女性管理職が少ないデータから学習すると、女性を管理職候補として低く評価)
- 表現バイアス: 特定のグループのサンプル数が少ない(例: 希少疾患患者のデータが不足)
- 測定バイアス: データ収集の方法自体に偏りがある(例: 特定地域でのみデータを収集)
対策:
-
データの多様性確保: バランスの取れたデータセットの構築
-
公平性指標の測定:
- Demographic Parity(統計的パリティ): すべてのグループで同じ割合で肯定的な判断がなされる
- Equal Opportunity(機会均等): 真にポジティブなケースで、すべてのグループが同じ確率で正しく判定される
- Equalized Odds(公平なオッズ): 真陽性率と偽陽性率が全グループで等しい
-
定期的な監査: AIの判断結果を属性別に分析し、不公平性を検出
-
再学習とチューニング: バイアスが検出された場合、モデルを修正
4. 人間による監督 (Human-in-the-Loop)
原則:
最終的な意思決定は人間が行う、あるいはAIの判断を人間がいつでも覆せるようにするなど、AIをあくまで支援ツールとして位置づける体制の構築が重要です。
実装レベル:
- Human-in-the-Loop (HITL): すべての判断に人間が関与
- Human-on-the-Loop (HOTL): AIが自動判断するが、人間が監視し、必要に応じて介入
- Human-out-of-the-Loop (HOOTL): 完全自動化(高リスク領域では推奨されない)
適用例:
- 医療診断: AIが診断候補を提示するが、最終的な診断は医師が行う
- 与信審査: AIがスコアリングするが、融資の最終判断は審査担当者が行う
- 採用: AIが書類選考で候補者をランク付けするが、面接と最終判断は人間が行う
センシティブな分野への影響
医療、金融、人事などのセンシティブな分野では、特に大きなインパクトが予想されます。
1. 医療分野
期待される効果:
- 創薬研究の加速: 電子カルテやゲノム情報を活用した創薬、診断支援AIの開発が飛躍的に進む
- 個別化医療: 患者一人ひとりのゲノムや病歴に基づいた最適な治療法の選択
- 医師の負担軽減: カルテ作成の自動化により、医師が患者ケアに集中できる
リスクと課題:
- 誤診のリスク: AIの「幻覚」による誤った診断情報の提供
- 遺伝情報に基づく差別: 保険加入や就職での不当な取り扱い
- 患者の同意: 医療データは最も機微な情報であり、たとえ匿名化されていても、患者の明示的な同意なく利用することへの倫理的懸念
必要な対応:
- 医療AIに対する薬機法承認の厳格化
- 遺伝情報差別禁止法の制定
- 医療倫理委員会による審査の義務化
2. 金融分野
期待される効果:
- 与信審査の高度化: 顧客の取引履歴や信用情報をAIで分析し、より精緻な審査が可能
- 不正検知の強化: 金融犯罪やマネーロンダリングをリアルタイムで検知
- パーソナライズされた金融商品: 顧客のライフステージや投資目的に合わせた商品提案
リスクと課題:
- ブラックボックス問題: アルゴリズムによる不透明な融資拒否(理由が説明されない)
- 金融排除: AIが特定の属性(年齢、居住地、職業など)を持つ人々を自動的に排除
- プロファイリングの拡大: 行動履歴から支払い能力を予測し、信用スコアに反映
必要な対応:
- 融資拒否時の理由説明義務(改正貸金業法で検討中)
- 金融庁による AI審査システムの監督強化
- 業界団体による自主規制ガイドラインの策定
3. 人事分野
期待される効果:
- 採用の効率化: AIによる書類選考で、採用担当者の負担を軽減
- 客観的な評価: 人間の主観的バイアスを排除し、公平な評価
- 最適な人材配置: 従業員のスキルと業務のマッチングを最適化
リスクと課題:
- 過去のバイアスの再生産: 歴史的に男性が多かった職種で、AIが女性を低く評価
- 年齢差別: 若年層を優遇するアルゴリズム
- プライバシー侵害: SNS投稿やオンライン行動を無断でスクレイピングし、評価に利用
必要な対応:
- 労働基準法の改正(AI採用の規制)
- 採用AIの公平性監査の義務化
- 候補者へのAI利用の事前通知と同意取得
今後の展望と課題
展望: AI産業の活性化
期待されるポジティブな影響:
- 国内AI産業の活性化: データアクセスが容易になることで、国内のAIスタートアップや研究機関が活性化
- 世界をリードするAIサービス: 医療、防災、製造業など、日本の強みを持つ分野で世界をリードするAIサービスが生まれる可能性
- データ利活用の成功事例: 社会全体としてAIの便益を享受できる場面が増える(例: 災害予測、高齢者ケア、環境保護)
具体例:
- Preferred Networksが医療画像診断AIで世界トップレベルの精度を達成
- ソフトバンクとトヨタの合弁会社MONETが、移動データを活用した最適な交通システムを構築
- 国立がん研究センターががんゲノムデータベースを構築し、個別化医療を実現
課題: 実効性の確保と国民の信頼
1. 実効性の確保
改正法の理念が、現場の運用で形骸化しないよう、以下の取り組みが必要です。
- 中小企業への支援: 安全管理措置やオプトアウト対応の負担を軽減するためのガイドラインとツール提供
- 監督体制の強化: 個人情報保護委員会の人員と予算を増強し、実効的な監督を可能に
- 罰則の厳格化: 違反企業への罰則を強化し、抑止力を高める
2. 国民の理解と信頼
多くの国民が、自身のデータがどのように利用されるのかを理解し、納得できるような十分な情報提供とコミュニケーションが不可欠です。
- 啓発活動: 学校教育や公共広告でのデータリテラシー教育
- 透明性の向上: 政府や企業が、AI開発の実態や成果を積極的に公開
- 市民参加: データ利活用のルール作りに、市民や消費者団体が参加できる仕組み
3. 技術の進展への追随
AIや匿名化技術は日進月歩です。将来登場する新たなリスクに、法制度やガイドラインが迅速に対応し続ける必要があります。
- 継続的な法改正: 技術の進展に合わせて、定期的に法律を見直し
- サンドボックス制度: 新技術を実験的に試せる規制の特例措置
- 国際連携: OECDやG7などの国際フレームワークとの整合性確保
4. 国際的なデータ流通
グローバルに事業を展開する企業にとって、各国の規制(特にGDPR)との整合性をどのように取るかが、引き続き重要な経営課題となります。
- 十分性認定の維持: EUから日本の個人情報保護法が「十分性」を持つと認定されていることを維持(2019年に相互認証)
- データ越境移転の仕組み: 標準契約条項(SCC)や拘束的企業準則(BCR)の整備
- 国際標準への準拠: ISO/IEC 27701(プライバシー情報管理)などの認証取得
まとめ
2026年の個人情報保護法改正は、日本のAI戦略における極めて重要な一歩です。AI学習目的での機微情報利用の緩和、オプトアウト方式の導入、匿名化基準の明確化により、国内のAI開発が大きく前進する可能性があります。
しかし、これは「イノベーション vs プライバシー」という単純な二項対立ではありません。両者を両立させ、信頼を基盤としたデータ利活用(トラスト)の体制を社会と共に構築していくことが、成功の鍵となります。
企業は、この法改正を単なる規制緩和として捉えるのではなく、倫理的な配慮を組み込んだデータガバナンスを実践する好機と捉え、以下の取り組みを進めるべきです。
企業が取るべきアクション:
- データガバナンス体制の構築: 責任者の明確化、社内教育、ライフサイクル管理
- プライバシー・バイ・デザインの実装: 企画段階からプライバシー保護を組み込む
- 透明性の確保: 平易な言葉での説明、オプトアウト手続きの簡便化
- 公平性の検証: AIのバイアス検証と継続的な改善
- 人間による監督: 最終判断は人間が行う体制の維持
2026年は、日本のAI開発が大きく飛躍する年になる可能性がある一方で、プライバシー保護と倫理的なデータ利用のあり方が社会全体で問われる年でもあります。政府、企業、市民が対話を重ね、信頼に基づいたデータ社会を構築していくことが求められます。
AI COMMONでは、お客様のビジネスに最適なAIソリューションの導入と、データガバナンス体制の構築をトータルでサポートしています。 個人情報保護法改正への対応、倫理的なAI開発、プライバシー影響評価など、ご検討の方は、ぜひお気軽にご相談ください。
関連記事
- 週間AIニュース(2026年1月12日週)- エージェントAIと規制の時代へ
- 2026年日本のAI主権(ソブリンAI)動向 - 国内完結型AIへの転換
- 2026年AIガバナンスと規制強化:企業に求められる対応と準備
参考文献
- 個人情報保護委員会 (PPC) 公式ウェブサイト
- TMI総合法律事務所 - 個人情報保護法改正解説
- 森・濱田松本法律事務所 - AI開発とデータ利用に関する法的考察
- 内閣府「AI戦略会議」議事録・配布資料
- 経済産業省「デジタル市場競争会議」報告書
- 特定非営利活動法人 Japan Privacy Professionals Association (JPPA) 声明
- OECD - "Privacy Framework"
- European Commission - GDPR公式文書
- 中国 個人情報保護法(2021年施行)
- California Consumer Privacy Act (CCPA) / California Privacy Rights Act (CPRA)